

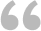
我们可能熟悉使用INDEX、SMALL等在给定单列或单行数组的情况下,返回满足一个或多个条件的值的列表。这是一项标准的公式技术。
我们可能熟悉使用INDEX、SMALL等在给定单列或单行数组的情况下,返回满足一个或多个条件的值的列表。这是一项标准的公式技术。

在《Excel公式练习32:将包含空单元格的多行多列单元格区域转换成单独的列并去掉空单元格》中,我们述了一种方法,给定由多个列组成的单元格区域,从该区域返回由所有非空单元格组成的单个列。可以很容易地验证,在该公式中的单个条件可以扩展到多个条件,因此,我们现在有了从一维数组和二维数组中生成单列列表的方法。
那么,可以更进一步吗?“三维”是经常应用于Excel中特定公式的通用术语,这些公式不仅可以对单列或单行进行操作,也可以对由多列或多行组成的单元格区域进行操作,还可以有效地对多个工作表进行操作。
本文提供了一种方法,在给定一个或多个相同布局的工作表的情况下,可以创建另一个“主”工作表,该工作表仅由满足特定条件的所有工作表中的数据组成。并且,这里不使用VBA,仅使用公式。
假设我们想从下面三个工作表中整理数据:
工作表Sheet1:
图1
工作表Sheet2:
图2
工作表Sheet3:
图3
想要创建一个主工作表Master,其数据来源于上面三个工作表中列D中的值为“Y”的数据:
图4
解决方案
首先,定义下面两个名称:
名称:Sheet3
引用位置:={“Sheet1″,”Sheet2″,”Sheet3”}
名称:Arry1
引用位置:=MMULT(0+(ROW(INDIRECT(“1:”&COUNTA(Sheets)))>=TRANSPOSE(ROW(INDIRECT(“1:”&COUNTA(Sheets))))),TRANSPOSE(COUNTIF(INDIRECT(“‘”&Sheets&”‘!D2:D10″),”Y”)))
可以根据实际情况,修改工作表列表和数据范围(D2:D10)。
在工作表Master的单元格G1中,输入下面的公式:
=SUMPRODUCT(COUNTIF(INDIRECT(“‘”&Sheets&”‘!D2:D10″),”Y”))
在工作表Master的单元格A2中输入下面的数组公式:
=IF(ROWS($1:1)>$G$1,””,INDEX(INDIRECT(“‘”&INDEX(Sheets,MATCH(TRUE,Arry1>=ROWS($1:1),0))&”‘!A2:F10”),SMALL(IF(INDIRECT(“‘”&INDEX(Sheets,MATCH(TRUE,Arry1>=ROWS($1:1),0))&”‘!D2:D10″)=”Y”,ROW(INDIRECT(“1:”&$G$1))),IFERROR(1+ROWS($1:1)-LOOKUP(ROWS($1:1),1+Arry1),ROWS($1:1))),COLUMNS($A:A)))
向下和向右拖放公式至合适的位置。
工作原理
先看看相对简单的单元格G1中的公式,该公式用于确定返回结果的数量:
=SUMPRODUCT(COUNTIF(INDIRECT(“‘”&Sheets&”‘!D2:D10″),”Y”))
如果不熟悉跨多个工作表使用公式的技术,那么应记下使用INDIRECT的这种公式构造,因为它实际上是我们执行此类计算的唯一方法。上述公式转换为:
=SUMPRODUCT(COUNTIF(INDIRECT(“‘”&{“Sheet1″,”Sheet2″,”Sheet3″}&”‘!D2:D10″),”Y”))
然后,将这组代表工作表名称的文本字符串的两端连接,在后面是所使用的工作表区域(D2:D10),在前面用单个撇号连接。尽管在工作表的名称中不包含空格的情况下,并不需要这样,但是这样做将更好更通用。这样,公式转换为:
=SUMPRODUCT(COUNTIF(INDIRECT({“‘Sheet1’!D2:D10″,”‘Sheet2’!D2:D10″,”‘Sheet3’!D2:D10″}),”Y”))
因为COUNTIF函数能够操作三维单元格区域,并且SUMPRODUCT函数提供了必要的强制转换,使得INDIRECT函数返回一组单元格引用,而不仅仅是一个,因此公式转换为:
=SUMPRODUCT({3,2,1})
其中数组的值由3、2、1组成,与工作表Sheet1、Sheet2、Sheet3的列D中包含“Y”的数量一致。该公式的最后结果为:
6
接下来,看看单元格A2中的主公式:
=IF(ROWS($1:1)>$G$1,””,INDEX(INDIRECT(“‘”&INDEX(Sheets,MATCH(TRUE,Arry1>=ROWS($1:1),0))&”‘!A2:F10”),SMALL(IF(INDIRECT(“‘”&INDEX(Sheets,MATCH(TRUE,Arry1>=ROWS($1:1),0))&”‘!D2:D10″)=”Y”,ROW(INDIRECT(“1:”&$G$1))),IFERROR(1+ROWS($1:1)-LOOKUP(ROWS($1:1),1+Arry1),ROWS($1:1))),COLUMNS($A:A)))
在IF函数中的前半部分很简单,如果拖放的行数超过了可能获得的结果数量,则为空。
在公式中使用了定义的名称Arry1:
=MMULT(0+(ROW(INDIRECT(“1:”&COUNTA(Sheets)))>=TRANSPOSE(ROW(INDIRECT(“1:”&COUNTA(Sheets))))),TRANSPOSE(COUNTIF(INDIRECT(“‘”&Sheets&”‘!D2:D10″),”Y”)))
这种公式构造可以有效地动态生成汇总小计,并且是使用标准的SUBTOTA/OFFSET函数组合的替代方法。
依次看看传递给MMULT函数的数组。第一个是:
0+(ROW(INDIRECT(“1:”&COUNTA(Sheets)))>=TRANSPOSE(ROW(INDIRECT(“1:”&COUNTA(Sheets)))))
转换为:
0+(ROW(INDIRECT(“1:”&3))>=TRANSPOSE(ROW(INDIRECT(“1:”&3))))
转换为:
0+({1;2;3}>=TRANSPOSE({1;2;3}))
转换为:
0+({1;2;3}>={1,2,3})
两个正交数组进行比较,一个是3行1列,一个是1行3列,得到一个3行3列的数组,该数组由9个TRUE/FALSE值组成:
0+({TRUE,FALSE,FALSE;TRUE,TRUE,FALSE;TRUE,TRUE,TRUE})
转换为1/0值组成的数组:
{1,0,0;1,1,0;1,1,1}
另外一个传递给MMULT函数的数组是:
TRANSPOSE(COUNTIF(INDIRECT(“‘”&Sheets&”‘!D2:D10″),”Y”))
转换为:
TRANSPOSE({3,2,1})
得到:
{3;2;1}
因此,MMULT函数变为:
MMULT({1,0,0;1,1,0;1,1,1},{3;2;1})
结果是:
{3;5;6}
使用Arry1的值来替换主公式中的相应部分,先看看公式中的:
INDIRECT(“‘”&INDEX(Sheets,MATCH(TRUE,Arry1>=ROWS($1:1),0))&”‘!A2:F10”)
转换为:
INDIRECT(“‘”&INDEX(Sheets,MATCH(TRUE,{3;5;6}>=1,0))&”‘!A2:F10”)
转换为:
INDIRECT(“‘”&INDEX(Sheets,1)&”‘!A2:F10”)
转换为:
INDIRECT(“‘”&”Sheet1″&”‘!A2:F10”)
转换为:
INDIRECT(“‘Sheet1’!A2:F10”)
因此,可以看到,对于A2中的公式,将返回Sheet1。例如,如果解构单元格A5中的公式,那么公式中的MATCH构造将如下所示:
MATCH(TRUE,Arry1>=ROWS($1:4),0)
唯一发生变化的是引用ROWS($1:4)而不是ROWS($1:1),结果转换为:
MATCH(TRUE,{3;5;6}>=4,0)
得到2,这样将引用工作表Sheet2。
实际上,该技术的核心为:通过生成动态汇总小计数量的数组,该小计数量由来自每个工作表中符合条件(即在列D中的值为“Y”)的行数组成,然后将公式所在单元格相对行数与该数组相比较,以便有效地确定公式所在行中要指定的工作表。因此,主公式中的子句:
INDEX(INDIRECT(“‘”&INDEX(Sheets,MATCH(TRUE,Arry1>=ROWS($1:1),0))&”‘!A2:F10”),SMALL(IF(INDIRECT(“‘”&INDEX(Sheets,MATCH(TRUE,Arry1>=ROWS($1:1),0))&”‘!D2:D10″)=”Y”,ROW(INDIRECT(“1:”&$G$1))),IFERROR(1+ROWS($1:1)-LOOKUP(ROWS($1:1),1+Arry1),ROWS($1:1))),COLUMNS($A:A))
可转换为:
INDEX(Sheet1!A2:F10,SMALL(IF(Sheet1!D2:D10=”Y”,ROW(INDIRECT(“1:”&$G$1))),IFERROR(1+ROWS($1:1)-LOOKUP(ROWS($1:1),1+Arry1),ROWS($1:1))),COLUMNS($A:A))
先看看上面公式中的SMALL函数部分:
IF(Sheet1!D2:D10=”Y”,ROW(INDIRECT(“1:”&$G$1)))
转换为:
IF({“Y”;0;”Y”;”Y”;0;0;0;0;0}=”Y”,ROW(INDIRECT(“1:”&6)))
转换为:
IF({TRUE;FALSE;TRUE;TRUE;FALSE;FALSE;FALSE;FALSE;FALSE},{1;2;3;4;5;6})
得到:
{1;FALSE;3;4;FALSE;FALSE;FALSE;FALSE;FALSE}
这里,可以看到数组中的1、3和4对应于工作表Sheet1列D中为“Y”的相对行号。现在要做的就是将该数组传递给SMALL函数并确定参数k,这实际上是整个解决方案中最难的部分,因为与我们将这种构造应用于由单列组成的数组不同(例如,在这种情况下,对于连续行,可以简单地将参数k增加1),而这里必须考虑:当要求Sheet2返回值时,以及要求Sheet3返回值时,该参数将被“重置”为1。为此,这里使用:
IFERROR(1+ROWS($1:1)-LOOKUP(ROWS($1:1),1+Arry1),ROWS($1:1))
为理解这个公式构造是如何工作的,我们可暂时将其作为独立的数组公式,输入到某单元格中,然后向下拖放以了解其生成的值。实际上,将该公式从A2向下拖至A7,可转换为:
IFERROR(1+{1,2,3,4,5,6}-LOOKUP({1,2,3,4,5,6},1+Arry1),{1,2,3,4,5,6})
转换为:
IFERROR(1+{1,2,3,4,5,6}-LOOKUP({1,2,3,4,5,6},1+{3;5;6}),{1,2,3,4,5,6})
转换为:
IFERROR(1+{1,2,3,4,5,6}-{#N/A,#N/A,#N/A,4,4,6},{1,2,3,4,5,6})
转换为:
=IFERROR({#N/A,#N/A,#N/A,1,2,1},{1,2,3,4,5,6})
得到:
{1,2,3,1,2,1}
正是我们需要的参数k的值,即在工作表Sheet1中匹配第1、第2和第3小的行,在工作表Sheet2中匹配第1和第2小的行,在工作表Sheet3中匹配第1小的行。
现在,回到主公式中的子句:
INDEX(INDIRECT(“‘”&INDEX(Sheets,MATCH(TRUE,Arry1>=ROWS($1:1),0))&”‘!A2:F10”),SMALL(IF(INDIRECT(“‘”&INDEX(Sheets,MATCH(TRUE,Arry1>=ROWS($1:1),0))&”‘!D2:D10″)=”Y”,ROW(INDIRECT(“1:”&$G$1))),IFERROR(1+ROWS($1:1)-LOOKUP(ROWS($1:1),1+Arry1),ROWS($1:1))),COLUMNS($A:A))
可转换为:
INDEX(Sheet1!A2:F10,SMALL({1;FALSE;3;4;FALSE;FALSE;FALSE;FALSE;FALSE},1),COLUMNS($A:A))
转换为:
INDEX(Sheet1!A2:F10,1,COLUMNS($A:A))
COLUMNS($A:A)使得公式向右拖放时,可以为INDEX函数的参数column_num提供合适的值。在单元格A2中,COLUMNS($A:A)的值等于1,因此公式转换为:
INDEX(Sheet1!A2:F10,1,1)
即工作表Sheet1中单元格A2的值。







