
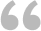
根据工作表中提供的2010年至2013年一些国家的人口数据,在单元格A1中使用一个公式来确定该期间人口平均年增长率最大的区域。
根据工作表中提供的2010年至2013年一些国家的人口数据,在单元格A1中使用一个公式来确定该期间人口平均年增长率最大的区域。

图1
公式要求:
1. 不仅结果正确,而且要使用最少的字符。
2. 必须同时包括行列引用,而不能只是行引用或列引用(例如3:2或A:F)。
3. 不允许使用名称。
先不看答案,自已动手试一试。
公式
在单元格A1中的数组公式为:
=LOOKUP(,0/FREQUENCY(0,1/MMULT(SUMIF(B3:B12,B3:B12,OFFSET(D3,,{0,1,2}))/SUMIF(B3:B12,B3:B12,OFFSET(C3,,{0,1,2})),{1;1;1})),B3:B4)
公式解析
这里,为了测量平均同比增长,实际计算任何形式的数学平均值并不是必需的。因此,只需为每个区域简单地计算该区域内所有国家的所有同比比率之和即可。公式结合使用MMULT、OFFSET和SUMIF函数来实现。
1. 先看看公式中的这部分:
SUMIF(B3:B12,B3:B12,OFFSET(D3,,{0,1,2}))
有效地执行了一系列三个不同的SUMIF计算,使用以下部分生成了参数sum_ranges的三个值:
OFFSET(D3,,{0,1,2}
对于OFFSET函数来说,一般情况下如果省略参数height和参数width意味着则默认它们的值为1。然而,在本例的情形下,它等价于:
OFFSET(D3,,{0,1,2},10)
这是由于将上面的结果构造传递给另一个函数(本例中为SUMIF函数),并且由于该函数要求其参数sum_range的大小和位移等于其参数range的大小和位移,因此Excel扩展了OFFSET函数生成的范围以满足该要求。
因此,虽然在正常情况下,公式中的构造:
OFFSET(D3,,{0,1,2}
会解析为由单个单元格引用组成的数组:
{D3,E3,F3}
但是,在本例中,Excel会接受每个引用并将其扩展为与指定单元格区域(即B3:B12)的大小相同,那么:
SUMIF(B3:B12,B3:B12,OFFSET(D3,,{0,1,2}))
解析为:
SUMIF(B3:B12,B3:B12,{D3:D12,E3:E12,F3:F12})
而不是通常的:
SUMIF(B3:B12,B3:B12,{D3,E3,F3})
这样,将返回一个10行3列的数组,其每列中的元素等于下面三个公式单独计算的结果:
SUMIF(B3:B12,B3:B12,D3:D12)
SUMIF(B3:B12,B3:B12,E3:E12)
SUMIF(B3:B12,B3:B12,F3:F12)
因此,公式中的构造:
SUMIF(B3:B12,B3:B12,OFFSET(D3,,{0,1,2}))
转换为:
{1345097171,1351670528,1358363416;8487319,8457915,8429700;22210006,22872070,23546083;6287968,6329821,6373552;1345097171,1351670528,1358363416;22210006,22872070,23546083;6287968,6329821,6373552;8487319,8457915,8429700;1345097171,1351670528,1358363416;8487319,8457915,8429700}
该数组的10行中每行的3个元素分别代表列B中每个区域相对应的列D、列E、列F中的数据之和,例如第一行中的{1345097171,1351670528,1358363416}是“East Asia &Pacific”对应的列D、列E和列F中数据的和,依此类推。
2. 要确定同比变化,只需生成与上述值相对应的值矩阵,但这一次是针对列C、列D和列E,然后将上面的数组中的每个值除以新数组中相应的元素。因此,通过与上述类似的逻辑,可以验证:
SUMIF(B3:B12,B3:B12,OFFSET(C3,,{0,1,2}))
转换为:
{1338663302,1345097171,1351670528;8522630,8487319,8457915;21558045,22210006,22872070;6249188,6287968,6329821;1338663302,1345097171,1351670528;21558045,22210006,22872070;6249188,6287968,6329821;8522630,8487319,8457915;1338663302,1345097171,1351670528;8522630,8487319,8457915}
3. 执行除法操作:
SUMIF(B3:B12,B3:B12,OFFSET(D3,,{0,1,2}))/SUMIF(B3:B12,B3:B12,OFFSET(C3,,{0,1,2}))
得到:
{1.00480618912193,1.00488690121556,1.00495156760568;0.995856795378891,0.996535537311606,0.996664071464421;1.03024212074889,1.02980926704837,1.02946882376628;1.00620560623236,1.00665604532339,1.00690872617093;1.00480618912193,1.00488690121556,1.00495156760568;1.03024212074889,1.02980926704837,1.02946882376628;1.00620560623236,1.00665604532339,1.00690872617093;0.995856795378891,0.996535537311606,0.996664071464421;1.00480618912193,1.00488690121556,1.00495156760568;0.995856795378891,0.996535537311606,0.996664071464421}
例如,在这个数组中的第一个值1.00480618912193表示2010年至2011年之间“East Asia & Pacific”区域的人口比例增长。
4. 为了确定这十个区域中哪个区域的同比平均值最高,只需要对代表每个区域的上述数组中的三个比例求和,并确定其中的最大值(如前所述,实际上无需计算这里的数学平均值)。这意味着将上述矩阵的十行中的每行中的三个元素相加,可使用MMULT实现,从而:
MMULT(SUMIF(B3:B12,B3:B12,OFFSET(D3,,{0,1,2}))/SUMIF(B3:B12,B3:B12,OFFSET(C3,,{0,1,2})),{1;1;1})
转换为:
MMULT({1.00480618912193,1.00488690121556,1.00495156760568;0.995856795378891,0.996535537311606,0.996664071464421;1.03024212074889,1.02980926704837,1.02946882376628;1.00620560623236,1.00665604532339,1.00690872617093;1.00480618912193,1.00488690121556,1.00495156760568;1.03024212074889,1.02980926704837,1.02946882376628;1.00620560623236,1.00665604532339,1.00690872617093;0.995856795378891,0.996535537311606,0.996664071464421;1.00480618912193,1.00488690121556,1.00495156760568;0.995856795378891,0.996535537311606,0.996664071464421},{1;1;1})
得到:
{3.01464465794317;2.98905640415492;3.08952021156354;3.01977037772668;3.01464465794317;3.08952021156354;3.01977037772668;2.98905640415492;3.01464465794317;2.98905640415492}
到这里,我们可能会想到使用标准的INDEX、MATCH和MAX函数组合技术来求出上述数组中的最大值:
=INDEX(B3:B12,MATCH(MAX(MMULT(SUMIF(B3:B12,B3:B12,OFFSET(D3,,{0,1,2}))/SUMIF(B3:B12,B3:B12,OFFSET(C3,,{0,1,2})),{1;1;1})),MMULT(SUMIF(B3:B12,B3:B12,OFFSET(D3,,{0,1,2}))/SUMIF(B3:B12,B3:B12,OFFSET(C3,,{0,1,2})),{1;1;1}),0))
然而,既然要寻找最简短的公式来解决问题,我们使用一项不同的技术:LOOKUP和FREQUENCY函数的组合,更简洁,也更令人惊奇!
5. 公式:
=LOOKUP(,0/FREQUENCY(0,1/MMULT(SUMIF(B3:B12,B3:B12,OFFSET(D3,,{0,1,2}))/SUMIF(B3:B12,B3:B12,OFFSET(C3,,{0,1,2})),{1;1;1})),B3:B4)
使用上面已经获取的中间值替换,可转换为:
=LOOKUP(,0/FREQUENCY(0,1/{3.01464465794317;2.98905640415492;3.08952021156354;3.01977037772668;3.01464465794317;3.08952021156354;3.01977037772668;2.98905640415492;3.01464465794317;2.98905640415492}),B3:B4)
转换为:
=LOOKUP(,0/FREQUENCY(0,{0.331714053716128;0.334553740307462;0.323674852896956;0.331151006505605;0.331714053716128;0.323674852896956;0.331151006505605;0.334553740307462;0.331714053716128;0.334553740307462}),B3:B4)
原理很简单,之前数组中的最大值除1后必然成为后面数组中的最小值。
通常,如果将值数组(都在0到1之间)作为参数bins_array的值传递给FREQUENCY函数,而将0作为其参数data_array的值,则1将赋给参数bins_array中的最小值,其余的将为空或为零。因此,公式转换为:
=LOOKUP(,0/{0;0;1;0;0;0;0;0;0;0;0},B3:B4)
转换为:
=LOOKUP(,{#DIV/0!;#DIV/0!;0;#DIV/0!;#DIV/0!;#DIV/0!;#DIV/0!;#DIV/0!;#DIV/0!;#DIV/0!;#DIV/0!},B3:B4)
这里,LOOKUP函数中忽略第一个参数lookup_value的值,这等效于指定该参数的值为0。
注意到,公式中并没有指定区域B3:B12,而是使用了缩小的单元格区域B3:B4,这与前面所的OFFSET函数的工作原理相同,Excel将单元格区域B3:B4自动扩展为所需的B3:B12。
最后得到的结果为:
Sub-Saharan Africa
小结
进一步理解SUMIF函数、OFFSET函数和LOOKUP函数的工作原理。







