

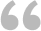
如下图1所示,在单元格区域A1:A10中有一些数据。现在,想从该区域中提取单词并创建唯一值列表,如列B中的数据所示。
如下图1所示,在单元格区域A1:A10中有一些数据。现在,想从该区域中提取单词并创建唯一值列表,如列B中的数据所示。

图1
可以在单元格B1中编写一个公式,向下拖拉以创建该唯一值列表。如何编写这个公式呢?
先不看答案,自已动手试一试。
公式
在单元格B1中输入数组公式:
=IF(ROWS($1:1)>$C$1,””,INDEX(Arry3,SMALL(IF(FREQUENCY(IF(Arry3<>””,MATCH(Arry3,Arry3,0)),Arry2),Arry2),ROWS($1:1))))
下拉直至出现空单元格为止。
在单元格C1中,下面的数组公式:
=SUM((Arry3<>””)/MMULT(0+(Arry3=TRANSPOSE(Arry3)),ROW(INDIRECT(“1:”& COUNTA(Arry3)))^0))
计算单元格区域A1:A10中不重复的单个单词的数量。
公式解析
公式中的Arry1、Arry2、Arry3是定义的三个名称。
名称:Arry1
引用位置:=1+LEN(Data)-LEN(SUBSTITUTE(Data,””,””))
名称:Arry2
引用位置:=ROW(INDIRECT(“1:” &(MAX(Arry1)*ROWS(Data))))
名称:Arry3
引用位置:=INDEX(TRIM(MID(SUBSTITUTE(Data,””,REPT(” “,999)),TRANSPOSE(999*(ROW(INDIRECT(“1:”&MAX(Arry1)))-1)+1),999)),N(IF(1,1+INT((Arry2-1)/MAX(Arry1)))),N(IF(1,1+MOD(Arry2-1,MAX(Arry1)))))
在上述名称中,使用了另一个定义的名称:Data
引用位置:=Sheet1!$A$1:$A$10
1. 我们首先来看一个名称Arry3,这是我们公式的关键部分。名称Arry3的定义公式:
=INDEX(TRIM(MID(SUBSTITUTE(Data,””,REPT(” “,999)),TRANSPOSE(999*(ROW(INDIRECT(“1:”&MAX(Arry1)))-1)+1),999)),N(IF(1,1+INT((Arry2-1)/MAX(Arry1)))),N(IF(1,1+MOD(Arry2-1,MAX(Arry1)))))
(1)使用TRIM、MID、SUBSTITUTE和REPT函数的构造是一种标准的(并且非常有用)组合,给定一个以某字符(空格、逗号、分号等)分隔的字符串,该构造能用于提取这些被分隔的子字符串中的任何一个,或者(像本例一样)生成由这些被分隔的子字符串的组成的数组,以便按我们希望的方式进行操作。
现在,仅将上述公式应用于Data中的第一个单元格,以了解其工作原理。我们还将用SUMPRODUCT封装该结构,不是因为真想对“Amaranth”、“Bronze”和“Silver”求和,而是使我们能够强制返回数组。因此,我们将使用的公式为:
=SUMPRODUCT(TRIM(MID(SUBSTITUTE(A1,” “,REPT(“”,99)),99*(ROW(INDIRECT(“1:” &1+LEN(A1)-LEN(SUBSTITUTE(A1,” “,””))))-1)+1,99)))
(为便于解释,这里将上面的999缩小为99。)
关于此公式构造的关键点是字符串中所有空格的初始替换,这次替换基本上使用更多的空格。如果所使用的字符串用逗号或分号分隔,则情况将相同:我们将用更多的空格替换所有逗号或分号。
这里,生成那些更多空格字符串的部分就是REPT(” ”,99),构成了一个包含99个空格的字符串。
使用空格替换后的公式为:
=SUMPRODUCT(TRIM(MID(“Amaranth Bronze Silver,99*(ROW(INDIRECT(“1:”& 1+LEN(A1)-LEN(SUBSTITUTE(A1,” “,””))))-1)+1,99)))
此时,在单词之间已放置了大量的空格。
再看看MID函数中参数start_num部分:
99*(ROW(INDIRECT(“1:” &1+LEN(A1)-LEN(SUBSTITUTE(A1,” “,””))))-1)+1
在单元格A1中字符串的长度是22,将单词之间的空格去掉后长度是20。因此:
1+LEN(A1)-LEN(SUBSTITUTE(A1,””,””))
的结果为:1+22-20,为3。
注意这种公式构造,该构造可以有效地计算字符串中(以空格分隔的)子字符串的数量。
这样,MID函数的参数start_num部分转换成:
99*(ROW(INDIRECT(“1:” & 3))-1)+1
即为:
99*({0;1;2})+1
结果为:
{1;100;199}
这样,可以确保本例中所拆分的单词都在空格分隔的区域内。其实,只要单词不长且我们选择的类似99这样的数字够大,都可以保证能够有效拆分单词。
实际上,可以保证有效获取分隔区域的数值的长度应该始终大于字符串中任何单个单词的长度。这样,我们可以选择该值为字符串的长度,因为单个子字符串的长度都不能大于整个字符串本身的长度。所以,建议在这种类型的公式结构中使用LEN(A1)而不是99,甚至999。本例中由于要将公式应用于一系列单元格,故没有使用该方法,而是直接取值999。
这里取MID函数的第三个参数为99,以保证能够将单词包含到我们获取到子字符串中。
这样,上面的SUMPRODUCT公式变为:
=SUMPRODUCT(TRIM(MID(“Amaranth Bronze Silver”,{1;100;199},99)))
转换为:
=SUMPRODUCT(TRIM({“Amaranth “;” Bronze “;” Silver”}))
TRIM函数去掉字符串前后的空格:
=SUMPRODUCT({“Amaranth“;”Bronze“;”Silver”})
好了!原理讲清楚了,现在回到名称Arry3:
=INDEX(TRIM(MID(SUBSTITUTE(Data,””,REPT(” “,999)),TRANSPOSE(999*(ROW(INDIRECT(“1:”&MAX(Arry1)))-1)+1),999)),N(IF(1,1+INT((Arry2-1)/MAX(Arry1)))),N(IF(1,1+MOD(Arry2-1,MAX(Arry1)))))
记住,我们没有传递单个单元格到TRIM(MID(SUBSTITUTE(中,而是单元格区域。先看看公式中MID函数的指定起始位置的参数部分:
TRANSPOSE(999*(ROW(INDIRECT(“1:”& MAX(Arry1)))-1)+1)
首先看看定义的名称Arry1:
1+LEN(Data)-LEN(SUBSTITUTE(Data,””,””))
转换为:
1+LEN({“Amaranth BronzeSilver”;”Bronze”;””;”Violet BronzeAmaranth”;”Red”;”Puce Bronze”;”Taupe Ochre BronzeCerise”;”Silver Red CeriseOrange”;””;”Cerise”})-LEN(SUBSTITUTE({“AmaranthBronze Silver”;”Bronze”;””;”Violet BronzeAmaranth”;”Red”;”Puce Bronze”;”Taupe Ochre BronzeCerise”;”Silver Red CeriseOrange”;””;”Cerise”},” “,””))
转换为:
1+{22;6;0;22;3;11;25;24;0;6}-{20;6;0;20;3;10;22;21;0;6}
结果为:
{3;1;1;3;1;2;4;4;1;1}
即单元格区域Data中每个单元格内单个单词的数量,除了其中第3行和第9行为空但仍返回不正确的数字1外。但由于我们只是想获取所构造的数组的最大值,因此这些不正确的结果不会对我们有影响。
这样,MID函数的指定起始位置的参数部分转换为:
TRANSPOSE(999*(ROW(INDIRECT(“1:” &MAX({3;1;1;3;1;2;4;4;1;1})))-1)+1)
转换为:
TRANSPOSE({1;1000;1999;2998})
结果为:
{1,1000,1999,2998}
此时,公式中的一部分转换为:
TRIM(MID(SUBSTITUTE(Data,””,REPT(” “,999)),{1,1000,1999,2998},999))
转换为:
TRIM({“Amaranth “,” Bronze “,” Silver”,””;”Bronze”,””,””,””;””,””,””,””;”Violet “,” Bronze “,” Amaranth”,””;”Red”,””,””,””;”Puce “,” Bronze”,””,””;”Taupe “,” Ochre “,” Bronze “,” Cerise”;”Silver “,” Red “,” Cerise “,” Orange”;””,””,””,””;”Cerise”,””,””,””})
这里为一个10行4列的数组。
下图2展示了MID函数运行的结果。
图2
TRIM函数使上述数组变为:
{“Amaranth”,”Bronze”,”Silver”,””;”Bronze”,””,””,””;””,””,””,””;”Violet”,”Bronze”,”Amaranth”,””;”Red”,””,””,””;”Puce”,”Bronze”,””,””;”Taupe”,”Ochre”,”Bronze”,”Cerise”;”Silver”,”Red”,”Cerise”,”Orange”;””,””,””,””;”Cerise”,””,””,””}
现在,创建了一个由单元格区域Data中所有单个子字符串(或单词)组成的数组,接着可以开始考虑处理该数组中的元素以达到我们的要求。
(2)下面,要考虑从数组中创建唯一值列表。我们有一些从列表中创建唯一值的标准公式,例如下图3所示。
图3
在单元格B2中,计算列表中返回的唯一值个数:
=SUMPRODUCT((A2:A10<>””)/(COUNTIF(A2:A10,A2:A10&””)))
在列D中,使用FREQUENCY函数来获取唯一值列表。在单元格D2中输入数组公式:
=IF(ROWS($1:1)>$B$2,””,INDEX($A$2:$A$10,SMALL(IF(FREQUENCY(IF($A$2:$A$10<>””,MATCH($A$2:$A$10,$A$2:$A$10,0)),ROW($A$2:$A$10)-MIN(ROW($A$2:$A$10))+1),ROW($A$2:$A$10)-MIN(ROW($A$2:$A$10))+1),ROWS($1:1))))
下拉至出现空单元格为止。
在列E中,使用COUNTIF函数来获取唯一值列表。在单元格E2中输入数组公式:
=IF(ROWS($1:1)>$B$2,””,INDEX($A$2:$A$10,MATCH(0,IF($A$2:$A$10<>””,COUNTIF(E$1:E1,$A$2:$A$10&””)),0)))
下拉至出现空单元格为止。
(作者个人倾向于使用第1个公式,更灵活且比COUNTIF版本要更快,特别是,想要从中获得唯一值的数组是从公式中的其他函数生成的数组的情形下。COUNTIF函数的缺点在于传递给它的参数必须是实际的工作表区域引用。)
从上面的示例中可以看出,FREQUENCY函数可以处理单行或单列数组,而我们这里生成的是10行4列数组,那么FREQUENCY函数可以处理这样的二维数组吗?不幸的是,答案是否定的。虽然INDEX、SMALL和FREQUENCY函数可以处理这类数组,但MATCH函数不能,传递给它的lookup_array参数必须是单行或单列。
因此,我们需要采用一种将这里的数组转换成单行或单列数组的技术。
(3)回到前面,现在定义名称Arry3的公式可以转换成:
INDEX({“Amaranth”,”Bronze”,”Silver”,””;”Bronze”,””,””,””;””,””,””,””;”Violet”,”Bronze”,”Amaranth”,””;”Red”,””,””,””;”Puce”,”Bronze”,””,””;”Taupe”,”Ochre”,”Bronze”,”Cerise”;”Silver”,”Red”,”Cerise”,”Orange”;””,””,””,””;”Cerise”,””,””,””},N(IF(1,1+INT((Arry2-1)/MAX(Arry1)))),N(IF(1,1+MOD(Arry2-1,MAX(Arry1)))))
我们可以看到,这里对INDEX的行参数和列参数使用了两个构造:
N(IF(1,1+INT((Arry2-1)/MAX(Arry1))))
和
N(IF(1,1+MOD(Arry2-1,MAX(Arry1))))
这里引用了名称Arry2:
ROW(INDIRECT(“1:”& (MAX(Arry1)*ROWS(Data))))
上文中已计算出Arry1的最大值为4,Data中的行数为10,因此上面的公式转换为:
ROW(INDIRECT(“1:” & 40))
于是,Arry2为由1至40组成的单列数组:
{1;2;3;4;5;6;7;8;9;10;11;12;13;14;15;16;17;18;19;20;21;22;23;24;25;26;27;28;29;30;31;32;33;34;35;36;37;38;39;40}
这样,上述构造中的:
1+INT((Arry2-1)/MAX(Arry1))
成为:
1+INT(({1;2;3;4;5;6;7;8;9;10;11;12;13;14;15;16;17;18;19;20;21;22;23;24;25;26;27;28;29;30;31;32;33;34;35;36;37;38;39;40}-1)/4)
转换为:
1+INT({0;0.25;0.5;0.75;1;1.25;1.5;1.75;2;2.25;2.5;2.75;3;3.25;3.5;3.75;4;4.25;4.5;4.75;5;5.25;5.5;5.75;6;6.25;6.5;6.75;7;7.25;7.5;7.75;8;8.25;8.5;8.75;9;9.25;9.5;9.75})
转换为:
1+{0;0;0;0;1;1;1;1;2;2;2;2;3;3;3;3;4;4;4;4;5;5;5;5;6;6;6;6;7;7;7;7;8;8;8;8;9;9;9;9}
结果为:
{1;1;1;1;2;2;2;2;3;3;3;3;4;4;4;4;5;5;5;5;6;6;6;6;7;7;7;7;8;8;8;8;9;9;9;9;10;10;10;10}
同样,列参数构造中的:
1+MOD(Arry2-1,MAX(Arry1))
可以转换为:
{1;2;3;4;1;2;3;4;1;2;3;4;1;2;3;4;1;2;3;4;1;2;3;4;1;2;3;4;1;2;3;4;1;2;3;4;1;2;3;4}
由于这两个数组都具有相同的向量位移(即它们都是单列数组),我们知道,将它们传递给INDEX函数进行处理时,这些数组中相对应的元素将被“配对”,因此我们将指示INDEX返回一个值数组,其row_num和col_num参数将依次为:1/1、1/2、1/3、1/4、2/1、2/2、2/3、2/4、3/1,…,依此类推。也就是说,我们将依次从上文生成的10行4列的数组中取值。
现在定义名称Arry3的公式可以转换成:
INDEX({“Amaranth”,”Bronze”,”Silver”,””;”Bronze”,””,””,””;””,””,””,””;”Violet”,”Bronze”,”Amaranth”,””;”Red”,””,””,””;”Puce”,”Bronze”,””,””;”Taupe”,”Ochre”,”Bronze”,”Cerise”;”Silver”,”Red”,”Cerise”,”Orange”;””,””,””,””;”Cerise”,””,””,””},{1;1;1;1;2;2;2;2;3;3;3;3;4;4;4;4;5;5;5;5;6;6;6;6;7;7;7;7;8;8;8;8;9;9;9;9;10;10;10;10},{1;2;3;4;1;2;3;4;1;2;3;4;1;2;3;4;1;2;3;4;1;2;3;4;1;2;3;4;1;2;3;4;1;2;3;4;1;2;3;4})
转换成最终的结果:
{“Amaranth”;”Bronze”;”Silver”;””;”Bronze”;””;””;””;””;””;””;””;”Violet”;”Bronze”;”Amaranth”;””;”Red”;””;””;””;”Puce”;”Bronze”;””;””;”Taupe”;”Ochre”;”Bronze”;”Cerise”;”Silver”;”Red”;”Cerise”;”Orange”;””;””;””;””;”Cerise”;””;””;””}
至此,成功地将原来的10行4列数组转换成40行1列的数组。这样,就可以将这个数组传递给MATCH函数而不会出错了。
注意,在上述构造中,前面的部分为N(IF(1,是为了强制INDEX返回数组,详细原因参见《Excel公式技巧03:INDEX函数,给公式提供数组》。
2. 使用Arry3替换掉上文中使用FREQUENCY函数求唯一值的公式中的单元格区域,并进行适当的调整,得到单元格B2中的公式:
=IF(ROWS($1:1)>$C$1,””,INDEX(Arry3,SMALL(IF(FREQUENCY(IF(Arry3<>””,MATCH(Arry3,Arry3,0)),Arry2),Arry2),ROWS($1:1))))
3. 对于单元格C1中求唯一值个数的公式:
=SUM((Arry3<>””)/MMULT(0+(Arry3=TRANSPOSE(Arry3)),ROW(INDIRECT(“1:”& COUNTA(Arry3)))^0))
(1)Arry3中的元素是否为空进行比较,得到数组:
{TRUE;TRUE;TRUE;FALSE;TRUE;FALSE;FALSE;FALSE;FALSE;FALSE;FALSE;FALSE;TRUE;TRUE;TRUE;FALSE;TRUE;FALSE;FALSE;FALSE;TRUE;TRUE;FALSE;FALSE;TRUE;TRUE;TRUE;TRUE;TRUE;TRUE;TRUE;TRUE;FALSE;FALSE;FALSE;FALSE;TRUE;FALSE;FALSE;FALSE}
(2)看看MMULT中的第二个数组:
ROW(INDIRECT(“1:” &COUNTA(Arry3)))^0
我们已经知道Arry3中元素个数为40,因此上述数组为:
{1;2;3;4;5;6;7;8;9;10;11;12;13;14;15;16;17;18;19;20;21;22;23;24;25;26;27;28;29;30;31;32;33;34;35;36;37;38;39;40}^0
结果为:
{1;1;1;1;1;1;1;1;1;1;1;1;1;1;1;1;1;1;1;1;1;1;1;1;1;1;1;1;1;1;1;1;1;1;1;1;1;1;1;1}
(3)看看MMULT中的第一个数组:
0+(Arry3=TRANSPOSE(Arry3))
这将转换成40行40列的数组。由于数组太大,为了方便解释其原理,将数据区域Data缩减为A1:A2,这样Arry3为:
{“Amaranth”;”Bronze”;”Silver”;”Bronze”;””;””}
此时,MMULT中的第一个数组转换为:
0+({“Amaranth”;”Bronze”;”Silver”;”Bronze”;””;””}={“Amaranth”,”Bronze”,”Silver”,”Bronze”,””,””})
两个正交数组比较后的结果为:
0+{TRUE,FALSE,FALSE,FALSE,FALSE,FALSE;FALSE,TRUE,FALSE,TRUE,FALSE,FALSE;FALSE,FALSE,TRUE,FALSE,FALSE,FALSE;FALSE,TRUE,FALSE,TRUE,FALSE,FALSE;FALSE,FALSE,FALSE,FALSE,TRUE,TRUE;FALSE,FALSE,FALSE,FALSE,TRUE,TRUE}
加上0强制转换为1/0组成的数组:
{1,0,0,0,0,0;0,1,0,1,0,0;0,0,1,0,0,0;0,1,0,1,0,0;0,0,0,0,1,1;0,0,0,0,1,1}
(4)此时,MMULT公式为:
MMULT({1,0,0,0,0,0;0,1,0,1,0,0;0,0,1,0,0,0;0,1,0,1,0,0;0,0,0,0,1,1;0,0,0,0,1,1},{1;1;1;1;1;1})
得到:
{1;2;1;2;2;2}
(5)此时,SUM公式为:
=SUM({TRUE;TRUE;TRUE;TRUE;FALSE;FALSE}/{1;2;1;2;2;2})
转换为:
=SUM({1;0.5;1;0.5;0;0})
结果为3。表明如果数据区域为A1:A2,有3个唯一值。
(6)回到示例中的数据区域A1:A10,此时的SUM公式为:
=SUM({TRUE;TRUE;TRUE;FALSE;TRUE;FALSE;FALSE;FALSE;FALSE;FALSE;FALSE;FALSE;TRUE;TRUE;TRUE;FALSE;TRUE;FALSE;FALSE;FALSE;TRUE;TRUE;FALSE;FALSE;TRUE;TRUE;TRUE;TRUE;TRUE;TRUE;TRUE;TRUE;FALSE;FALSE;FALSE;FALSE;TRUE;FALSE;FALSE;FALSE}/{2;5;2;21;5;21;21;21;21;21;21;21;1;5;2;21;2;21;21;21;1;5;21;21;1;1;5;3;2;2;3;1;21;21;21;21;3;21;21;21})
转换为:
=SUM({0.5;0.2;0.5;0;0.2;0;0;0;0;0;0;0;1;0.2;0.5;0;0.5;0;0;0;1;0.2;0;0;1;1;0.2;0.333333333333333;0.5;0.5;0.333333333333333;1;0;0;0;0;0.333333333333333;0;0;0})
结果为10。表明数据区域A1:A10中有10个唯一值。
小结
解决本案例的过程是,首先从原来的以空格分隔的字符串中生成子字符串数组,重新构建该数组,以便能够对其进行处理。我们从本案例中至少可以学到:
1. 使用大量的空格替换来拆分由分隔符分隔的字符串。
2. 从列表中获取唯一值的标准公式。
3. 将二维数组转换成一维数组的方法。







