

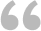
如下图1所示,在单元格A1中有一段英文文本,其中可能包含标点符号或不包含标点符号,在单元格B1中输入一个公式,识别文本中包含五个元音字母的单词,统计出这些单词的个数。
如下图1所示,在单元格A1中有一段英文文本,其中可能包含标点符号或不包含标点符号,在单元格B1中输入一个公式,识别文本中包含五个元音字母的单词,统计出这些单词的个数。

图1
注意,统计的单词应满足:
1. 单词中包含全部五个元音字母
2. 这五个元音字母在单词中从左至右出现的顺序是a、e、i、o、u
3. 这五个元音字母在单词中只出现一次
在图1中,红色字体的单词满足条件,而黑色斜体的单词虽然包含全部的五个元音字母但由于顺序不符合要求,因此不满足条件。
先不看答案,自已动手试一试。
公式
在单元格B1中输入公式:
=SUMPRODUCT(0+(MMULT(0+(LEN(Arry2)-LEN(SUBSTITUTE(Arry2,{“a”,”e”,”i”,”o”,”u”},””))=1),{1;1;1;1;1})=5),0+(ISNUMBER(SEARCH(“a*e*i*o*u”,Arry2))))
公式解析
公式中的Arry1和Arry2是定义的两个名称。
名称:Arry1
引用位置:=ROW(INDIRECT(“1:”&1+LEN($A1)-LEN(SUBSTITUTE($A1,””,””))))-1
名称:Arry2
引用位置:=TRIM(MID(SUBSTITUTE(LOWER($A1),””,REPT(” “,LEN($A1))),LEN($A1)*Arry1+1,LEN($A1)))
注意,在定义名称时确保活动单元格位于工作表的第一行。
首先,来看看名称Arry1:
=ROW(INDIRECT(“1:” & 1+LEN($A1)-LEN(SUBSTITUTE($A1,””,””))))-1
由于单元格A1中字符串的长度为461,去掉空格后的长度为392,因此公式转换为:
=ROW(INDIRECT(“1:” & 1+461-392))-1
转换为:
=ROW(INDIRECT(“1:”& 70))-1
转换为:
{1;2;3;4;5;6;7;8;9;10;11;12;13;14;15;16;17;18;19;20;21;22;23;24;25;26;27;28;29;30;31;32;33;34;35;36;37;38;39;40;41;42;43;44;45;46;47;48;49;50;51;52;53;54;55;56;57;58;59;60;61;62;63;64;65;66;67;68;69;70}-1
结果为:
{0;1;2;3;4;5;6;7;8;9;10;11;12;13;14;15;16;17;18;19;20;21;22;23;24;25;26;27;28;29;30;31;32;33;34;35;36;37;38;39;40;41;42;43;44;45;46;47;48;49;50;51;52;53;54;55;56;57;58;59;60;61;62;63;64;65;66;67;68;69}
中间获得的数组中的70对应着文本包含有70个子字符串(单词)。
将得到的结果数组传递给名称Arry2中MID函数的start_num参数:
=TRIM(MID(SUBSTITUTE(LOWER($A1),””,REPT(” “,LEN($A1))),LEN($A1)*Arry1+1,LEN($A1)))
注意,这里使用LOWER函数将文本转换成小写,因为SUBSTITUTE函数区分大小写。
Arry2将生成由A1中的单词组成的数组,其运行原理在本系列前面的文章中已作详细讲解,有兴趣的朋友可查阅参考。Arry2生成的数组为:
{“abstemious”;”people”;”who”;”are”;”not”;”facetious”;”by”;”nature”;”should”;”not”;”be”;”lacking”;”the”;”education”;”imbibing”;”of”;”arsenious”;”substances”;”will”;”not”;”make”;”them”;”more”;”abstentious.”;”indeed,”;”facetiousness”;”aside,”;”such”;”practices”;”are”;”likely”;”to”;”be”;”harmful,”;”as”;”many”;”acheilous”;”casualties”;”can”;”testify.”;”a”;”more”;”reliable”;”herbal”;”remedy”;”is”;”a”;”concoction”;”of”;”the”;”caesious,”;”annelidous”;”plants”;”found”;”anemious”;”plains”;”of”;”outer”;”mongolia,”;”plants”;”which”;”are”;”thought”;”to”;”contributed”;”to”;”the”;”diet”;”of”;”raeticodactylus.”}
数组中,有些单词包含了标点符号,但并不影响最终的结果。
下面,我们需要对上面生成的数组中的每个元素执行两项测试:第一项测试是确定每个元素是否按顺序包含“a”、“e”、“i”、“o”、“u”这五个元素,第二项测试确定这五个元音字母在元素中仅出现一次。
先看看公式中的:
ISNUMBER(SEARCH(“a*e*i*o*u”,Arry2))
SEARCH函数有一个很好的特性,接受通配符。因此,在合适的地方插入通配符后,可以使用字符串“a*e*i*o*u”作为该函数的find_text参数。这样,如果在查找的字符串中按顺序包含“a”、“e”、“i”、“o”、“u”这五个元素的话,则返回代表找到字符位置的数字。上述公式可转换为:
{TRUE;FALSE;FALSE; FALSE; FALSE; TRUE; FALSE; FALSE; FALSE; FALSE;FALSE; FALSE; FALSE; FALSE; FALSE; FALSE; TRUE; FALSE;FALSE; FALSE; FALSE; FALSE; FALSE; TRUE; FALSE; TRUE; FALSE; FALSE; FALSE; FALSE; FALSE; FALSE; FALSE;FALSE; FALSE; FALSE; TRUE; FALSE; FALSE; FALSE; FALSE;FALSE; FALSE; FALSE; FALSE; FALSE; FALSE; FALSE; FALSE; FALSE; TRUE; TRUE; FALSE; FALSE; TRUE; FALSE; FALSE; FALSE; FALSE; FALSE; FALSE; FALSE;FALSE; FALSE; FALSE; FALSE; FALSE; FALSE; FALSE; TRUE}
我们将数组中的TRUE采用红色字体,与Arry2中相应的元素对应:
{“abstemious”;”people”;”who”;”are”;”not”;”facetious”;”by”;”nature”;”should”;”not”;”be”;”lacking”;”the”;”education”;”imbibing”;”of”;”arsenious”;”substances”;”will”;”not”;”make”;”them”;”more”;”abstentious.”;”indeed,”;”facetiousness”;”aside,”;”such”;”practices”;”are”;”likely”;”to”;”be”;”harmful,”;”as”;”many”;”acheilous”;”casualties”;”can”;”testify.”;”a”;”more”;”reliable”;”herbal”;”remedy”;”is”;”a”;”concoction”;”of”;”the”;”caesious,”;”annelidous”;”plants”;”found”;”anemious”;”plains”;”of”;”outer”;”mongolia,”;”plants”;”which”;”are”;”thought”;”to”;”contributed”;”to”;”the”;”diet”;”of”;”raeticodactylus.”}
显然,这些红色字体的元素满足我们的条件,但并不是所有都满足,其中有两个“facetiousness”和“raeticodactylus.”中有些元音多于一个。
这样,我们需要进行第二项测试:
MMULT(0+(LEN(Arry2)-LEN(SUBSTITUTE(Arry2,{“a”,”e”,”i”,”o”,”u”},””))=1),{1;1;1;1;1})=5
这是一个标准的公式技术,用来确定字符串中某个字符有多少个:使用原始字符串的长度减去剔除掉指定字符后的字符串的长度。
注意到,我们要确定的字符不是一个而是五个。
对于LEN(Arry2),转换为原始字符串的长度:
{10;6;3;3;3;9;2;6;6;3;2;7;3;9;8;2;9;10;4;3;4;4;4;12;7;13;6;4;9;3;6;2;2;8;2;4;9;10;3;8;1;4;8;6;6;2;1;10;2;3;9;10;6;5;8;6;2;5;9;6;5;3;7;2;11;2;3;4;2;16}
公式中的:
LEN(SUBSTITUTE(Arry2,{“a”,”e”,”i”,”o”,”u”},””)
传递由五个值组成的数组给SUBSTITUTE函数的参数old_text,要确保这五个值组成的数组与Arry2正交。由于Arry2是单列数组向量,那么这五个数组应该是单行数组向量。这样,就形成了一个69行5列的数组,对应着每个单词删除一个元音字母后的字符串。例如,生成的数组的第一行应该为:
{“bstemious”,”abstmious”,”abstemous”,”abstemius”,”abstemios”}
最终的结果为:
{9,9,9,9,9;6,4,6,5,6;3,3,3,2,3;2,2,3,3,3;3,3,3,2,3;8,8,8,8,8;2,2,2,2,2;5,5,6,6,5;6,6,6,5,5;3,3,3,2,3;2,1,2,2,2;6,7,6,7,7;3,2,3,3,3;8,8,8,8,8;8,8,5,8,8;2,2,2,1,2;8,8,8,8,8;9,9,10,10,9;4,4,3,4,4;3,3,3,2,3;3,3,4,4,4;4,3,4,4,4;4,3,4,3,4;11,11,11,11,11;7,5,6,7,7;12,11,12,12,12;5,5,5,6,6;4,4,4,4,3;8,8,8,9,9;2,2,3,3,3;6,5,5,6,6;2,2,2,1,2;2,1,2,2,2;7,8,8,8,7;1,2,2,2,2;3,4,4,4,4;8,8,8,8,8;8,9,9,10,9;2,3,3,3,3;8,7,7,8,8;0,1,1,1,1;4,3,4,3,4;7,6,7,8,8;5,5,6,6,6;6,4,6,6,6;2,2,1,2,2;0,1,1,1,1;10,10,9,7,10;2,2,2,1,2;3,2,3,3,3;8,8,8,8,8;9,9,9,9,9;5,6,6,6,6;5,5,5,4,4;7,7,7,7,7;5,6,5,6,6;2,2,2,1,2;5,4,5,4,4;8,9,8,7,9;5,6,6,6,6;5,5,4,5,5;2,2,3,3,3;7,7,7,6,6;2,2,2,1,2;11,10,10,10,10;2,2,2,1,2;3,2,3,3,3;4,3,3,4,4;2,2,2,1,2;14,15,15,15,15}
从上面生成的第一个数组减去第二个数组,等于由每个元素中分别包含五个元音的数量组成的数组。例如第一个数组的第一个元素10(即单词”abstemious”的长度)减去第二个数组中的第一行{9,9,9,9,9}(即单词”abstemious”分别去掉五个元音后的长度):
10-{9,9,9,9,9}
得到:
{1,1,1,1,1}
也就是单词”abstemious”中元音”a”,”e”,”i”,”o”,”u”的个数组成的数组。
最终的结果为:
{1,1,1,1,1;0,2,0,1,0;0,0,0,1,0;1,1,0,0,0;0,0,0,1,0;1,1,1,1,1;0,0,0,0,0;1,1,0,0,1;0,0,0,1,1;0,0,0,1,0;0,1,0,0,0;1,0,1,0,0;0,1,0,0,0;1,1,1,1,1;0,0,3,0,0;0,0,0,1,0;1,1,1,1,1;1,1,0,0,1;0,0,1,0,0;0,0,0,1,0;1,1,0,0,0;0,1,0,0,0;0,1,0,1,0;1,1,1,1,1;0,2,1,0,0;1,2,1,1,1;1,1,1,0,0;0,0,0,0,1;1,1,1,0,0;1,1,0,0,0;0,1,1,0,0;0,0,0,1,0;0,1,0,0,0;1,0,0,0,1;1,0,0,0,0;1,0,0,0,0;1,1,1,1,1;2,1,1,0,1;1,0,0,0,0;0,1,1,0,0;1,0,0,0,0;0,1,0,1,0;1,2,1,0,0;1,1,0,0,0;0,2,0,0,0;0,0,1,0,0;1,0,0,0,0;0,0,1,3,0;0,0,0,1,0;0,1,0,0,0;1,1,1,1,1;1,1,1,1,1;1,0,0,0,0;0,0,0,1,1;1,1,1,1,1;1,0,1,0,0;0,0,0,1,0;0,1,0,1,1;1,0,1,2,0;1,0,0,0,0;0,0,1,0,0;1,1,0,0,0;0,0,0,1,1;0,0,0,1,0;0,1,1,1,1;0,0,0,1,0;0,1,0,0,0;0,1,1,0,0;0,0,0,1,0;2,1,1,1,1}
代表着每个单词中元音”a”,”e”,”i”,”o”,”u”分别出现的个数。
由于我们感兴趣的仅仅是这五个元音只出现一次的单词,将上面的数组与1相比较:
LEN(Arry2)-LEN(SUBSTITUTE(Arry2,{“a”,”e”,”i”,”o”,”u”},””))=1
得到:
{TRUE,TRUE,TRUE,TRUE,TRUE;FALSE,FALSE,FALSE,TRUE,FALSE;FALSE,FALSE,FALSE,TRUE,FALSE;TRUE,TRUE,FALSE,FALSE,FALSE;FALSE,FALSE,FALSE,TRUE,FALSE;TRUE,TRUE,TRUE,TRUE,TRUE;FALSE,FALSE,FALSE,FALSE,FALSE;TRUE,TRUE,FALSE,FALSE,TRUE;FALSE,FALSE,FALSE,TRUE,TRUE;FALSE,FALSE,FALSE,TRUE,FALSE;FALSE,TRUE,FALSE,FALSE,FALSE;TRUE,FALSE,TRUE,FALSE,FALSE;FALSE,TRUE,FALSE,FALSE,FALSE;TRUE,TRUE,TRUE,TRUE,TRUE;FALSE,FALSE,FALSE,FALSE,FALSE;FALSE,FALSE,FALSE,TRUE,FALSE;TRUE,TRUE,TRUE,TRUE,TRUE;TRUE,TRUE,FALSE,FALSE,TRUE;FALSE,FALSE,TRUE,FALSE,FALSE;FALSE,FALSE,FALSE,TRUE,FALSE;TRUE,TRUE,FALSE,FALSE,FALSE;FALSE,TRUE,FALSE,FALSE,FALSE;FALSE,TRUE,FALSE,TRUE,FALSE;TRUE,TRUE,TRUE,TRUE,TRUE;FALSE,FALSE,TRUE,FALSE,FALSE;TRUE,FALSE,TRUE,TRUE,TRUE;TRUE,TRUE,TRUE,FALSE,FALSE;FALSE,FALSE,FALSE,FALSE,TRUE;TRUE,TRUE,TRUE,FALSE,FALSE;TRUE,TRUE,FALSE,FALSE,FALSE;FALSE,TRUE,TRUE,FALSE,FALSE;FALSE,FALSE,FALSE,TRUE,FALSE;FALSE,TRUE,FALSE,FALSE,FALSE;TRUE,FALSE,FALSE,FALSE,TRUE;TRUE,FALSE,FALSE,FALSE,FALSE;TRUE,FALSE,FALSE,FALSE,FALSE;TRUE,TRUE,TRUE,TRUE,TRUE;FALSE,TRUE,TRUE,FALSE,TRUE;TRUE,FALSE,FALSE,FALSE,FALSE;FALSE,TRUE,TRUE,FALSE,FALSE;TRUE,FALSE,FALSE,FALSE,FALSE;FALSE,TRUE,FALSE,TRUE,FALSE;TRUE,FALSE,TRUE,FALSE,FALSE;TRUE,TRUE,FALSE,FALSE,FALSE;FALSE,FALSE,FALSE,FALSE,FALSE;FALSE,FALSE,TRUE,FALSE,FALSE;TRUE,FALSE,FALSE,FALSE,FALSE;FALSE,FALSE,TRUE,FALSE,FALSE;FALSE,FALSE,FALSE,TRUE,FALSE;FALSE,TRUE,FALSE,FALSE,FALSE;TRUE,TRUE,TRUE,TRUE,TRUE;TRUE,TRUE,TRUE,TRUE,TRUE;TRUE,FALSE,FALSE,FALSE,FALSE;FALSE,FALSE,FALSE,TRUE,TRUE;TRUE,TRUE,TRUE,TRUE,TRUE;TRUE,FALSE,TRUE,FALSE,FALSE;FALSE,FALSE,FALSE,TRUE,FALSE;FALSE,TRUE,FALSE,TRUE,TRUE;TRUE,FALSE,TRUE,FALSE,FALSE;TRUE,FALSE,FALSE,FALSE,FALSE;FALSE,FALSE,TRUE,FALSE,FALSE;TRUE,TRUE,FALSE,FALSE,FALSE;FALSE,FALSE,FALSE,TRUE,TRUE;FALSE,FALSE,FALSE,TRUE,FALSE;FALSE,TRUE,TRUE,TRUE,TRUE;FALSE,FALSE,FALSE,TRUE,FALSE;FALSE,TRUE,FALSE,FALSE,FALSE;FALSE,TRUE,TRUE,FALSE,FALSE;FALSE,FALSE,FALSE,TRUE,FALSE;FALSE,TRUE,TRUE,TRUE,TRUE}
将布尔值转换成数字:
{1,1,1,1,1;0,0,0,1,0;0,0,0,1,0;1,1,0,0,0;0,0,0,1,0;1,1,1,1,1;0,0,0,0,0;1,1,0,0,1;0,0,0,1,1;0,0,0,1,0;0,1,0,0,0;1,0,1,0,0;0,1,0,0,0;1,1,1,1,1;0,0,0,0,0;0,0,0,1,0;1,1,1,1,1;1,1,0,0,1;0,0,1,0,0;0,0,0,1,0;1,1,0,0,0;0,1,0,0,0;0,1,0,1,0;1,1,1,1,1;0,0,1,0,0;1,0,1,1,1;1,1,1,0,0;0,0,0,0,1;1,1,1,0,0;1,1,0,0,0;0,1,1,0,0;0,0,0,1,0;0,1,0,0,0;1,0,0,0,1;1,0,0,0,0;1,0,0,0,0;1,1,1,1,1;0,1,1,0,1;1,0,0,0,0;0,1,1,0,0;1,0,0,0,0;0,1,0,1,0;1,0,1,0,0;1,1,0,0,0;0,0,0,0,0;0,0,1,0,0;1,0,0,0,0;0,0,1,0,0;0,0,0,1,0;0,1,0,0,0;1,1,1,1,1;1,1,1,1,1;1,0,0,0,0;0,0,0,1,1;1,1,1,1,1;1,0,1,0,0;0,0,0,1,0;0,1,0,1,1;1,0,1,0,0;1,0,0,0,0;0,0,1,0,0;1,1,0,0,0;0,0,0,1,1;0,0,0,1,0;0,1,1,1,1;0,0,0,1,0;0,1,0,0,0;0,1,1,0,0;0,0,0,1,0;0,1,1,1,1}
现在要找到数组中由5个1组成的行,使用MMULT函数:
MMULT(0+(LEN(Arry2)-LEN(SUBSTITUTE(Arry2,{“a”,”e”,”i”,”o”,”u”},””))=1),{1;1;1;1;1})
得到:
{5;1;1;2;1;5;0;3;2;1;1;2;1;5;0;1;5;3;1;1;2;1;2;5;1;4;3;1;3;2;2;1;1;2;1;1;5;3;1;2;1;2;2;2;0;1;1;1;1;1;5;5;1;2;5;2;1;3;2;1;1;2;2;1;4;1;1;2;1;4}
我们将数组中为5的与Arry2中相应的元素对应:
{“abstemious”;”people”;”who”;”are”;”not”;”facetious”;”by”;”nature”;”should”;”not”;”be”;”lacking”;”the”;”education”;”imbibing”;”of”;”arsenious”;”substances”;”will”;”not”;”make”;”them”;”more”;”abstentious.”;”indeed,”;”facetiousness”;”aside,”;”such”;”practices”;”are”;”likely”;”to”;”be”;”harmful,”;”as”;”many”;”acheilous”;”casualties”;”can”;”testify.”;”a”;”more”;”reliable”;”herbal”;”remedy”;”is”;”a”;”concoction”;”of”;”the”;”caesious,”;”annelidous”;”plants”;”found”;”anemious”;”plains”;”of”;”outer”;”mongolia,”;”plants”;”which”;”are”;”thought”;”to”;”contributed”;”to”;”the”;”diet”;”of”;”raeticodactylus.”}
有9个结果满足,但只满足单词中出现五个元音字母一次而不满足其按”a”,”e”,”i”,”o”,”u”的顺序出现。
将上面的数组与5比较,得到:
{TRUE;FALSE;FALSE;FALSE;FALSE;TRUE;FALSE;FALSE;FALSE;FALSE;FALSE;FALSE;FALSE;TRUE;FALSE;FALSE;TRUE;FALSE;FALSE;FALSE;FALSE;FALSE;FALSE;TRUE;FALSE;FALSE;FALSE;FALSE;FALSE;FALSE;FALSE;FALSE;FALSE;FALSE;FALSE;FALSE;TRUE;FALSE;FALSE;FALSE;FALSE;FALSE;FALSE;FALSE;FALSE;FALSE;FALSE;FALSE;FALSE;FALSE;TRUE;TRUE;FALSE;FALSE;TRUE;FALSE;FALSE;FALSE;FALSE;FALSE;FALSE;FALSE;FALSE;FALSE;FALSE;FALSE;FALSE;FALSE;FALSE;FALSE}
将上面得到的两个条件的结果代入公式:
=SUMPRODUCT(0+(MMULT(0+(LEN(Arry2)-LEN(SUBSTITUTE(Arry2,{“a”,”e”,”i”,”o”,”u”},””))=1),{1;1;1;1;1})=5),0+(ISNUMBER(SEARCH(“a*e*i*o*u”,Arry2))))
得到:
=SUMPRODUCT(0+{TRUE;FALSE;FALSE;FALSE;FALSE;TRUE;FALSE;FALSE;FALSE;FALSE;FALSE;FALSE;FALSE;TRUE;FALSE;FALSE;TRUE;FALSE;FALSE;FALSE;FALSE;FALSE;FALSE;TRUE;FALSE;FALSE;FALSE;FALSE;FALSE;FALSE;FALSE;FALSE;FALSE;FALSE;FALSE;FALSE;TRUE;FALSE;FALSE;FALSE;FALSE;FALSE;FALSE;FALSE;FALSE;FALSE;FALSE;FALSE;FALSE;FALSE;TRUE;TRUE;FALSE;FALSE;TRUE;FALSE;FALSE;FALSE;FALSE;FALSE;FALSE;FALSE;FALSE;FALSE;FALSE;FALSE;FALSE;FALSE;FALSE;FALSE}),0+{TRUE;FALSE; FALSE; FALSE; FALSE; TRUE; FALSE; FALSE;FALSE; FALSE; FALSE; FALSE; FALSE; FALSE; FALSE; FALSE; TRUE; FALSE; FALSE;FALSE; FALSE; FALSE; FALSE; TRUE; FALSE; TRUE; FALSE; FALSE; FALSE; FALSE;FALSE; FALSE; FALSE; FALSE; FALSE; FALSE; TRUE; FALSE; FALSE; FALSE; FALSE;FALSE; FALSE; FALSE; FALSE; FALSE; FALSE; FALSE; FALSE; FALSE; TRUE; TRUE;FALSE; FALSE; TRUE; FALSE; FALSE; FALSE; FALSE; FALSE; FALSE; FALSE; FALSE;FALSE; FALSE; FALSE; FALSE; FALSE; FALSE; TRUE })
得到:
=SUMPRODUCT({1;0;0;0;0;1;0;0;0;0;0;0;0;1;0;0;1;0;0;0;0;0;0;1;0;0;0;0;0;0;0;0;0;0;0;0;1;0;0;0;0;0;0;0;0;0;0;0;0;0;1;1;0;0;1;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0},{1;0;0;0;0;1;0;0;0;0;0;0;0;0;0;0;1;0;0;0;0;0;0;1;0;1;0;0;0;0;0;0;0;0;0;0;1;0;0;0;0;0;0;0;0;0;0;0;0;0;1;1;0;0;1;0;0;0;0;0;0;0;0;0;0;0;0;0;0;1})
结果为:
8







