

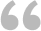
本次的练习是:如下图1所示,单元格区域A2:E5中包含一系列值和空单元格,其中有重复值,要求从该单元格区域中生成按字母顺序排列的不重复值列表,如图1中G列所示。
本次的练习是:如下图1所示,单元格区域A2:E5中包含一系列值和空单元格,其中有重复值,要求从该单元格区域中生成按字母顺序排列的不重复值列表,如图1中G列所示。

图1
在单元格G1中编写一个公式,下拉生成所要求的列表。
先不看答案,自已动手试一试。
公式
在单元格G1中的公式为:
=IF(ROWS($1:1)>$H$1,””,INDEX(Arry4,MATCH(SMALL(IF(FREQUENCY(IF(Range1<>””,MATCH(Range1,Arry4,0)),Arry1),COUNTIF(Range1,”<“&Arry4)),ROWS($1:1)),IF(Arry4<>””,COUNTIF(Range1,”<“&Arry4)),0)))
下拉直至出现空单元格为止。
在单元格H1中的公式为:
=SUMPRODUCT((Range1<>””)/COUNTIF(Range1,Range1&””))
公式中使用了5个名称,分别为:
名称:Range1
引用位置:=$A$2:$E$5
名称:Arry1
引用位置:=ROW(INDIRECT(“1:”&COLUMNS(Range1)*ROWS(Range1)))
名称:Arry2
引用位置:=1+INT((Arry1-1)/COLUMNS(Range1))
名称:Arry3
引用位置:=1+MOD(Arry1-1,COLUMNS(Range1))
名称:Arry4
引用位置:=INDEX(Range1,N(IF(1,Arry2)),N(IF(1,Arry3)))
公式解析
1. 在单元格H1中的公式比较直接,是一个获取列表区域唯一值数量的标准公式:
=SUMPRODUCT((Range1<>””)/COUNTIF(Range1,Range1&””))
转换为:
=SUMPRODUCT(({“Due”,””,”Otto”,””,”Otto”;””,””,””,””,”Tre”;”Sei”,”Cinque”,””,”Quattro”,”Otto”;”Due”,””,””,”Quattro”,”Otto”}<>””)/COUNTIF(Range1,Range1&””))
转换为:
=SUMPRODUCT({TRUE,FALSE,TRUE,FALSE,TRUE;FALSE,FALSE,FALSE,FALSE,TRUE;TRUE,TRUE,FALSE,TRUE,TRUE;TRUE,FALSE,FALSE,TRUE,TRUE}/COUNTIF(Range1,Range1&””))
接着解析COUNTIF部分,该部分计算Range1中每个条目在该区域内出现的次数:
=SUMPRODUCT({TRUE,FALSE,TRUE,FALSE,TRUE;FALSE,FALSE,FALSE,FALSE,TRUE;TRUE,TRUE,FALSE,TRUE,TRUE;TRUE,FALSE,FALSE,TRUE,TRUE}/{2,9,4,9,4;9,9,9,9,1;1,1,9,2,4;2,9,9,2,4})
除法运算后:
=SUMPRODUCT({0.5,0,0.25,0,0.25;0,0,0,0,1;1,1,0,0.5,0.25;0.5,0,0,0.5,0.25})
结果为:
6
2. 在单元格G1的主公式中:
=IF(ROWS($1:1)>$H$1,””,
如果公式向下拖拉的行数超过单元格H1中的数值6,则返回空值。
3. 下面重点看看公式中的:
INDEX(Arry4,MATCH(SMALL(IF(FREQUENCY(IF(Range1<>””,MATCH(Range1,Arry4,0)),Arry1),COUNTIF(Range1,”<“&Arry4)),ROWS($1:1)),IF(Arry4<>””,COUNTIF(Range1,”<“&Arry4)),0))
实际上,这是提取唯一且按字母顺序排列的值的标准公式构造,唯一区别是提取值的区域不是单列、一维区域,而是二维区域。然而,在原理上该技术是相同的:首先将二维区域转换成一维区域,然后应用通用的结构来获取我们想要的结果。
上述公式构造中的Arry4为:
INDEX(Range1,N(IF(1,Arry2)),N(IF(1,Arry3)))
这里,只是简单地索引二维区域中的每个元素。然而,我们得到的结果数组将是一维数组且包含的元素与二维区域中的元素完全相同。
为了解构Arry4,我们需要首先查看Arry2和Arry3,它们分别对应着INDEX函数的参数row_num和参数column_num。而它们都引用了Arry1:
=ROW(INDIRECT(“1:”&COLUMNS(Range1)*ROWS(Range1)))
名称Range1代表的区域有4行5列,因此转换为:
ROW(INDIRECT(“1:”&5*4))
得到:
{1;2;3;4;5;6;7;8;9;10;11;12;13;14;15;16;17;18;19;20}
再看Arry2:
=1+INT((Arry1-1)/COLUMNS(Range1))
转换为:
1+INT(({1;2;3;4;5;6;7;8;9;10;11;12;13;14;15;16;17;18;19;20}-1)/5)
转换为:
1+INT({0;1;2;3;4;5;6;7;8;9;10;11;12;13;14;15;16;17;18;19}/5)
转换为:
1+INT({0;0.2;0.4;0.6;0.8;1;1.2;1.4;1.6;1.8;2;2.2;2.4;2.6;2.8;3;3.2;3.4;3.6;3.8})
转换为:
1+{0;0;0;0;0;1;1;1;1;1;2;2;2;2;2;3;3;3;3;3}
得到:
{1;1;1;1;1;2;2;2;2;2;3;3;3;3;3;4;4;4;4;4}
接着看Arry3:
=1+MOD(Arry1-1,COLUMNS(Range1))
转换为:
1+MOD({0;1;2;3;4;5;6;7;8;9;10;11;12;13;14;15;16;17;18;19},5)
转换为:
1+{0;1;2;3;4;0;1;2;3;4;0;1;2;3;4;0;1;2;3;4}
得到:
{1;2;3;4;5;1;2;3;4;5;1;2;3;4;5;1;2;3;4;5}
再回到Arry4。可以转换为:
INDEX(Range1,N(IF(1,{1;1;1;1;1;2;2;2;2;2;3;3;3;3;3;4;4;4;4;4})),N(IF(1,{1;2;3;4;5;1;2;3;4;5;1;2;3;4;5;1;2;3;4;5})))
这里使用了强制INDEX返回数组的技术,详情可参阅《Excel公式技巧03:INDEX函数,给公式提供数组》。上述公式可转换为:
INDEX(Range1,{1;1;1;1;1;2;2;2;2;2;3;3;3;3;3;4;4;4;4;4},{1;2;3;4;5;1;2;3;4;5;1;2;3;4;5;1;2;3;4;5})
现在应该可以看清楚为INDEX函数的每个参数传递数组的原因了,因为上述公式等价于执行下列每个公式:
INDEX(Range1,1,1)
INDEX(Range1,1,2)
INDEX(Range1,1,3)
INDEX(Range1,1,4)
INDEX(Range1,1,5)
INDEX(Range1,2,1)
INDEX(Range1,2,2)
…
INDEX(Range1,4,5)
因此,Arry4的结果为:
{“Due”;””;”Otto”;””;”Otto”;””;””;””;””;”Tre”;”Sei”;”Cinque”;””;”Quattro”;”Otto”;”Due”;””;””;”Quattro”;”Otto”}
而Excel将Range1解析为:
{“Due”,””,”Otto”,””,”Otto”;””,””,””,””,”Tre”;”Sei”,”Cinque”,””,”Quattro”,”Otto”;”Due”,””,””,”Quattro”,”Otto”}
我们可以看到这两个数组中的值没有任何区别。唯一不同的是,Range1包含一个4行5列的二维数组,而Arry4是通过简单地将Range1中的每个元素进行索引而得出的,实际上是20行1列的一维区域。
好了,现在就可以使用我们掌握的常用的适用于一维区域的技术来操作该数组了!
4. 再看看主公式中的:
INDEX(Arry4,MATCH(SMALL(IF(FREQUENCY(IF(Range1<>””,MATCH(Range1,Arry4,0)),Arry1),COUNTIF(Range1,”<“&Arry4)),ROWS($1:1)),IF(Arry4<>””,COUNTIF(Range1,”<“&Arry4)),0))
先看看这部分:
IF(Range1<>””,MATCH(Range1,Arry4,0))
转换为:
IF({TRUE,FALSE,TRUE,FALSE,TRUE;FALSE,FALSE,FALSE,FALSE,TRUE;TRUE,TRUE,FALSE,TRUE,TRUE;TRUE,FALSE,FALSE,TRUE,TRUE},MATCH(Range1,Arry4,0))
使用Range1和Arry4替换,得到:
IF({TRUE,FALSE,TRUE,FALSE,TRUE;FALSE,FALSE,FALSE,FALSE,TRUE;TRUE,TRUE,FALSE,TRUE,TRUE;TRUE,FALSE,FALSE,TRUE,TRUE},MATCH({“Due”,””,”Otto”,””,”Otto”;””,””,””,””,”Tre”;”Sei”,”Cinque”,””,”Quattro”,”Otto”;”Due”,””,””,”Quattro”,”Otto”},{“Due”;””;”Otto”;””;”Otto”;””;””;””;””;”Tre”;”Sei”;”Cinque”;””;”Quattro”;”Otto”;”Due”;””;””;”Quattro”;”Otto”},0))
可转换为:
IF({TRUE,FALSE,TRUE,FALSE,TRUE;FALSE,FALSE,FALSE,FALSE,TRUE;TRUE,TRUE,FALSE,TRUE,TRUE;TRUE,FALSE,FALSE,TRUE,TRUE},{1,#N/A,3,#N/A,3;#N/A,#N/A,#N/A,#N/A,10;11,12,#N/A,14,3;1,#N/A,#N/A,14,3})
得到:
{1,FALSE,3,FALSE,3;FALSE,FALSE,FALSE,FALSE,10;11,12,FALSE,14,3;1,FALSE,FALSE,14,3}
这个数组是FREQUENCY函数的第一个参数,而Arry1是其第二个参数:
FREQUENCY(IF(Range1<>””,MATCH(Range1,Arry4,0)),Arry1)
可转换为:
FREQUENCY({1,FALSE,3,FALSE,3;FALSE,FALSE,FALSE,FALSE,10;11,12,FALSE,14,3;1,FALSE,FALSE,14,3},Arry1)
将Arry1代入:
FREQUENCY({1,FALSE,3,FALSE,3;FALSE,FALSE,FALSE,FALSE,10;11,12,FALSE,14,3;1,FALSE,FALSE,14,3},{1;2;3;4;5;6;7;8;9;10;11;12;13;14;15;16;17;18;19;20})
生成数组:
{2;0;4;0;0;0;0;0;0;1;1;1;0;2;0;0;0;0;0;0;0}
这是我们使用的相当标准的技术:上述数组中非零值的位置表示在该区域内每个不同值在该数组中的首次出现,因此提供了一种仅返回唯一值的方法。将该数组作为IF函数的条件:
IF(FREQUENCY(IF(Range1<>””,MATCH(Range1,Arry4,0)),Arry1),COUNTIF(Range1,”<“&Arry4))
转换为:
IF({2;0;4;0;0;0;0;0;0;1;1;1;0;2;0;0;0;0;0;0;0},COUNTIF(Range1,”<“&Arry4))
COUNTIF函数用于确定字母排序:
IF({2;0;4;0;0;0;0;0;0;1;1;1;0;2;0;0;0;0;0;0;0},{1;0;3;0;3;0;0;0;0;10;9;0;0;7;3;1;0;0;7;3})
结果为:
{1;FALSE;3;FALSE;FALSE;FALSE;FALSE;FALSE;FALSE;10;9;0;FALSE;7;FALSE;FALSE;FALSE;FALSE;FALSE;FALSE;FALSE}
这样,INDEX函数部分现在变成:
INDEX(Arry4,MATCH(SMALL({1;FALSE;3;FALSE;FALSE;FALSE;FALSE;FALSE;FALSE;10;9;0;FALSE;7;FALSE;FALSE;FALSE;FALSE;FALSE;FALSE;FALSE},ROWS($1:1)),IF(Arry4<>””,COUNTIF(Range1,”<“&Arry4)),0))
对于SMALL函数,其参数k的值由ROWS($1:1)指定,在单元格G1中为1,因此上述公式转换为:
INDEX(Arry4,MATCH(0,IF(Arry4<>””,COUNTIF(Range1,”<“&Arry4)),0))
转换为:
INDEX(Arry4,MATCH(0,IF(Arry4<>””,{1;0;3;0;3;0;0;0;0;10;9;0;0;7;3;1;0;0;7;3},0))
转换为:
INDEX(Arry4,MATCH(0,{1;FALSE;3;FALSE;3;FALSE;FALSE;FALSE;FALSE;10;9;0;FALSE;7;3;1;FALSE;FALSE;7;3},0))
转换为:
INDEX(Arry4,12)
将Arry4代入:
INDEX({“Due”;””;”Otto”;””;”Otto”;””;””;””;””;”Tre”;”Sei”;”Cinque”;””;”Quattro”;”Otto”;”Due”;””;””;”Quattro”;”Otto”},12)
得到结果:
Cinque
小结:
本文至少复习/使用了以下公式技术:
1. 统计列表区域中唯一值数量。
2. 将二维区域转换成一维区域。
3. 强制INDEX返回数组。
4. 确定字母排序。
5. 提取唯一值并按字母排序。







