

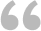
数据挖掘是一种从信息化社会的庞大数据中,挖掘宝藏的方法和程序,那么怎样从少量样本中挖掘重要信息呢?在面对许多数据时,怎样使用最佳的方法进行分析至关重要;若没有合适的数据,则必须从收集数据着手。此时,你会因为收集庞大的数据非常困难而放弃数据挖掘吗?
数据挖掘是一种从信息化社会的庞大数据中,挖掘宝藏的方法和程序,那么怎样从少量样本中挖掘重要信息呢?在面对许多数据时,怎样使用最佳的方法进行分析至关重要;若没有合适的数据,则必须从收集数据着手。此时,你会因为收集庞大的数据非常困难而放弃数据挖掘吗?

首先,请大家检验一项问卷调查的结果.有本书叫《日本的开关》 (庆应义塾大学佐藤稚彦研究室著,每日新闻社,2004),其中记载了用手机收集的问卷调查的统计结果。此项调查利用手机询问被调查者喜欢两者中的哪一个(选择),然后公布调查出来的比例。特点在于,利用手机快速传递信息的功能,在极短的时间内免费从2-3万的庞大人群中获得回答。
具体的调查内容如下所示,请读者也试着回答一下。
问题1:“日本”的读音,你喜欢“NIHON”还是“NIPPON”?
有22936名回答者;其中,喜欢“NIHON”的占61%,喜欢“NIPPON”的占39%。使用回答者多达2-3万人的“日本的开关”的调查问卷,询问43名数据挖掘同仁的意见。那么,结果与“日本的开关”有没有差异呢(如下图1和图2)? 关于“日本”读音的问题,回答结果是,“NIlHON”=70%,“NIPPON”=30%(图2No.2)。回答者比例是43/02936,不足“日本的开关”的总体回答者的0.2%。但是,从回答结果看,两者都是“NIHON”的比例居高,具有相同倾向。两者的相对误差都是15%。
对10项不同类别的内容进行问卷调查,请回答者从a、b中选择其中一个。然后,比较样本数很多(2万件以上)与样本数很少时(43件)的结果有何不同。
结果如图2所示。只有43名样本数的调查与“日本的开关”调查的选择a、b的倾向是一致的。而且相对误差比例都在20%以下。针对所有问题的回答情况,两者没有较大差异。也就是说,样本数多时和样本数少时的回答结果的倾向大致相同。当然,收集数据时要特别注意不能出別偏差。如果使用随机抽样,可以判断即使是少量样本数,与超过它500倍的庞大样本数的结果具有相同倾向。因此,在没有大量数据的情况下,可以把少量数据看做缩略图,以此捕捉样本倾向,进行预测。
【图1 】
【图2】
大家是不是认为数据挖掘一定需要收集大量数据呢?请先从用Excel分析身边的数据开始吧,前提是清楚数据分析是做什么的!用少量样本数分析,也可以把握倾向和类型。学会收集分析身边的数据并加以灵活运用非常重要。从笔者以往的经验来看,即使只存在少量数据,也叮从中得到十分有用的信息。







