

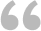
有一个包含数字和空的单元格区域,如下图1所示示例的单元格区域A1:F6,要求生成这些数字的唯一值,并按数字出现的频率顺序排列,出现频率高的排在前面,如果几个数字出现的频率相同,则数字小的排在前面,如图1中列I所示。
有一个包含数字和空的单元格区域,如下图1所示示例的单元格区域A1:F6,要求生成这些数字的唯一值,并按数字出现的频率顺序排列,出现频率高的排在前面,如果几个数字出现的频率相同,则数字小的排在前面,如图1中列I所示。

图1
先不看答案,自已动手试一试。
公式
在单元格I1中的数组公式为:
=IF(ROWS($1:1)>$H$1,””,MIN(IF(IF(Range1<>””,COUNTIF(Range1,Range1)+1/(Range1*10^6))=LARGE(IF(INDEX(FREQUENCY(0+(Range1&0),0+(Range1&0)),N(IF(1,COLUMNS(Range1)*Arry2-TRANSPOSE(COLUMNS(Range1)-Arry1)))),IF(Range1<>””,COUNTIF(Range1,Range1)+1/(Range1*10^6))),ROWS($1:1)),Range1)))
向下拖拉至出现空单元格为止。
单元格H1中为返回的数字数量,公式为:
=SUMPRODUCT((Range1<>””)/COUNTIF(Range1,Range1&””))
公式解析
在公式中,使用了3个名称,分别为:
名称:Range1
引用位置:=$A$1:$F$6
名称:Arry1
引用位置:=ROW(INDIRECT(“1:”&COLUMNS(Range1)))
名称:Arry2
引用位置:=ROW(INDIRECT(“1:”&ROWS(Range1)))
单元格H1中的公式是一种用于确定单元格区域内不同元素数量的标准公式结构。公式:
=SUMPRODUCT((Range1<>””)/COUNTIF(Range1,Range1&””))
转换为:
=SUMPRODUCT(({1,””,1,””,6,6;1,5,””,””,””,6;””,””,2,2,2,””;4,4,””,””,””,2;””,3,””,4,””,””;5,5,5,5,5,2}<>””)/COUNTIF(Range1,Range1&””))
转换为:
=SUMPRODUCT(({TRUE,FALSE,TRUE,FALSE,TRUE,TRUE;TRUE,TRUE,FALSE,FALSE,FALSE,TRUE;FALSE,FALSE,TRUE,TRUE,TRUE,FALSE;TRUE,TRUE,FALSE,FALSE,FALSE,TRUE;FALSE,TRUE,FALSE,TRUE,FALSE,FALSE;TRUE,TRUE,TRUE,TRUE,TRUE,TRUE})/COUNTIF(Range1,Range1&””))
公式中的COUNTIF(Range1,Range1&””)用来计算Range1区域中每个元素出现的次数,注意到在COUNTIF函数的第2个参数中添加了空字符串,其主要原因详解如下:
假设不添加空字符串,则为:
COUNTIF(Range1,Range1)
Excel首先会解析其第二个参数criteria:
COUNTIF(Range1,{1,0,1,0,6,6;1,5,0,0,0,6;0,0,2,2,2,0;4,4,0,0,0,2;0,3,0,4,0,0;5,5,5,5,5,2}))
然后解析其第一个参数range:
COUNTIF({1,””,1,””,6,6;1,5,””,””,””,6;””,””,2,2,2,””;4,4,””,””,””,2;””,3,””,4,””,””;5,5,5,5,5,2},{1,0,1,0,6,6;1,5,0,0,0,6;0,0,2,2,2,0;4,4,0,0,0,2;0,3,0,4,0,0;5,5,5,5,5,2}))
由于在第一个数组中没有0,因此结果为:
{3,0,3,0,3,3;3,6,0,0,0,3;0,0,5,5,5,0;3,3,0,0,0,5;0,1,0,3,0,0;6,6,6,6,6,5}
这意味着,将其作为除法的分母时,结果数组中将包含#DIV/0!,这将导致SUMPRODUCT函数出错。
通过在第二个参数指定的值后添加一个空字符串,Excel将空单元格解析为空字符串而不是0,因此公式:
COUNTIF(Range1,Range1&””)
解析为:
COUNTIF(Range1,{“1″,””,”1″,””,”6″,”6″;”1″,”5″,””,””,””,”6″;””,””,”2″,”2″,”2″,””;”4″,”4″,””,””,””,”2″;””,”3″,””,”4″,””,””;”5″,”5″,”5″,”5″,”5″,”2″})
这样,已转换的:
=SUMPRODUCT(({TRUE,FALSE,TRUE,FALSE,TRUE,TRUE;TRUE,TRUE,FALSE,FALSE,FALSE,TRUE;FALSE,FALSE,TRUE,TRUE,TRUE,FALSE;TRUE,TRUE,FALSE,FALSE,FALSE,TRUE;FALSE,TRUE,FALSE,TRUE,FALSE,FALSE;TRUE,TRUE,TRUE,TRUE,TRUE,TRUE})/COUNTIF(Range1,Range1&””))
转换为:
=SUMPRODUCT({TRUE,FALSE,TRUE,FALSE,TRUE,TRUE;TRUE,TRUE,FALSE,FALSE,FALSE,TRUE;FALSE,FALSE,TRUE,TRUE,TRUE,FALSE;TRUE,TRUE,FALSE,FALSE,FALSE,TRUE;FALSE,TRUE,FALSE,TRUE,FALSE,FALSE;TRUE,TRUE,TRUE,TRUE,TRUE,TRUE}/{3,15,3,15,3,3;3,6,15,15,15,3;15,15,5,5,5,15;3,3,15,15,15,5;15,1,15,3,15,15;6,6,6,6,6,5})
转换为:
=SUMPRODUCT({0.333333333333333,0,0.333333333333333,0,0.333333333333333,0.333333333333333;0.333333333333333,0.166666666666667,0,0,0,0.333333333333333;0,0,0.2,0.2,0.2,0;0.333333333333333,0.333333333333333,0,0,0,0.2;0,1,0,0.333333333333333,0,0;0.166666666666667,0.166666666666667,0.166666666666667,0.166666666666667,0.166666666666667,0.2})
得到结果:
6
因此,将单元格I1中的公式向下拖拉时,超过6个单元格将返回空,也就是公式的开头部分:
=IF(ROWS($1:1)>$H$1,””,
下面看看公式中的主要构造:
MIN(IF(IF(Range1<>””,COUNTIF(Range1,Range1)+1/(Range1*10^6))=LARGE(IF(INDEX(FREQUENCY(0+(Range1&0),0+(Range1&0)),N(IF(1,COLUMNS(Range1)*Arry2-TRANSPOSE(COLUMNS(Range1)-Arry1)))),IF(Range1<>””,COUNTIF(Range1,Range1)+1/(Range1*10^6))),ROWS($1:1)),Range1))
其中的:
COUNTIF(Range1,Range1)+1/(Range1*10^6)
将为单元格区域内的每个值生成一个计数数组,这很重要,因为问题的症结在于根据值在该区域内的频率返回值。使用额外的子句的原因是为我们提供一种方法,使我们可以区分在区域内两个或多个值出现频率相同的情况。更重要的是,此子句的目的是在这种情况下首先返回较小的值。
上述部分公式转换为:
{3,0,3,0,3,3;3,6,0,0,0,3;0,0,5,5,5,0;3,3,0,0,0,5;0,1,0,3,0,0;6,6,6,6,6,5}+1/({1000000,0,1000000,0,6000000,6000000;1000000,5000000,0,0,0,6000000;0,0,2000000,2000000,2000000,0;4000000,4000000,0,0,0,2000000;0,3000000,0,4000000,0,0;5000000,5000000,5000000,5000000,5000000,2000000})
注意,如果区域内有任何空字符串,那么这里将会解析为#VALUE!错误,然而该部分之前的IF子句——IF(Range1<>””将意味着不会考虑这些错误值。上面的结果转换为:
{3,0,3,0,3,3;3,6,0,0,0,3;0,0,5,5,5,0;3,3,0,0,0,5;0,1,0,3,0,0;6,6,6,6,6,5}+{0.000001,#DIV/0!,0.000001,#DIV/0!,1.66666666666667E-07,1.66666666666667E-07;0.000001,0.0000002,#DIV/0!,#DIV/0!,#DIV/0!,1.66666666666667E-07;#DIV/0!,#DIV/0!,0.0000005,0.0000005,0.0000005,#DIV/0!;0.00000025,0.00000025,#DIV/0!,#DIV/0!,#DIV/0!,0.0000005;#DIV/0!,3.33333333333333E-07,#DIV/0!,0.00000025,#DIV/0!,#DIV/0!;0.0000002,0.0000002,0.0000002,0.0000002,0.0000002,0.0000005}
得到:
{3.000001,#DIV/0!,3.000001,#DIV/0!,3.00000016666667,3.00000016666667;3.000001,6.0000002,#DIV/0!,#DIV/0!,#DIV/0!,3.00000016666667;#DIV/0!,#DIV/0!,5.0000005,5.0000005,5.0000005,#DIV/0!;3.00000025,3.00000025,#DIV/0!,#DIV/0!,#DIV/0!,5.0000005;#DIV/0!,1.00000033333333,#DIV/0!,3.00000025,#DIV/0!,#DIV/0!;6.0000002,6.0000002,6.0000002,6.0000002,6.0000002,5.0000005}
同样,其中的任何错误值将在下面解决:
IF(Range1<>””,COUNTIF(Range1,Range1)+1/(Range1*10^6))
转换为:
{3.000001,FALSE,3.000001,FALSE,3.00000016666667,3.00000016666667;3.000001,6.0000002,FALSE,FALSE,FALSE,3.00000016666667;FALSE,FALSE,5.0000005,5.0000005,5.0000005,FALSE;3.00000025,3.00000025,FALSE,FALSE,FALSE,5.0000005;FALSE,1.00000033333333,FALSE,3.00000025,FALSE,FALSE;6.0000002,6.0000002,6.0000002,6.0000002,6.0000002,5.0000005}
在此数组中,例如值3.000001、3.00000016666667和3.00000025分别表示在Range1内出现的1、6和4这三个值,其小数部分可进行区分。
现在,我们需要一种方法,该方法可用于从该数组中标识唯一值并将它们按降序排列,即:
6.0000002
5.0000005
3.000001
3.00000025
3.00000016666667
1.00000033333333
然后将它们与原始值进行匹配,我们知道上述值分别代表5出现了6次、2出现了5次、1出现了3次、4出现了3次、6出现了3次、3出现了1次。
为了将我们的数组限制为仅考虑唯一值的数组,公式中使用以下部分:
FREQUENCY(0+(Range1&0),0+(Range1&0))
将转换为:
{3;15;0;0;3;0;0;6;0;0;0;0;0;0;5;0;0;0;3;0;0;0;0;0;0;1;0;0;0;0;0;0;0;0;0;0;0}
在上面的数组中我们突出显示了非零值,与下面数组中突出显示值相对应(忽略数组维度):
{1,””,1,””,6,6;1,5,””,””,””,6;””,””,2,2,2,””;4,4,””,””,””,2;””,3,””,4,””,””;5,5,5,5,5,2}
也就是说,第一个数组中的非零值与每个不同的值在第二个数组中第一次出现相对应,对于空字符串也是如此。
可以看到,这种情形下使用FREQUENCY函数,从而将数组简化为每个值在该数组中出现次数的数组。公式中之所以在区域后添加0,是为了将空单元格转换为0。
现在,将FREQUENCY函数生成的数组传递给IF函数,以使结果数组仅包含不同的数值:
IF(FREQUENCY(0+(Range1&0),0+(Range1&0)),IF(Range1<>””,COUNTIF(Range1,Range1)+1/(Range1*10^6)))
转换为:
IF({3;15;0;0;3;0;0;6;0;0;0;0;0;0;5;0;0;0;3;0;0;0;0;0;0;1;0;0;0;0;0;0;0;0;0;0;0},{3.000001,FALSE,3.000001,FALSE,3.00000016666667,3.00000016666667;3.000001,6.0000002,FALSE,FALSE,FALSE,3.00000016666667;FALSE,FALSE,5.0000005,5.0000005,5.0000005,FALSE;3.00000025,3.00000025,FALSE,FALSE,FALSE,5.0000005;FALSE,1.00000033333333,FALSE,3.00000025,FALSE,FALSE;6.0000002,6.0000002,6.0000002,6.0000002,6.0000002,5.0000005})
结果是:
{3.000001,FALSE,3.000001,FALSE,3.00000016666667,3.00000016666667;3.000001,6.0000002,FALSE,FALSE,FALSE,3.00000016666667;FALSE,FALSE,FALSE,FALSE,FALSE,FALSE;FALSE,FALSE,FALSE,FALSE,FALSE,FALSE;FALSE,1.00000033333333,FALSE,3.00000025,FALSE,FALSE;FALSE,FALSE,FALSE,FALSE,FALSE,FALSE;FALSE,FALSE,FALSE,FALSE,FALSE,FALSE;#N/A,#N/A,#N/A,#N/A,#N/A,#N/A;FALSE,FALSE,FALSE,FALSE,FALSE,FALSE;FALSE,FALSE,FALSE,FALSE,FALSE,FALSE;FALSE,FALSE,FALSE,FALSE,FALSE,FALSE;FALSE,FALSE,FALSE,FALSE,FALSE,FALSE;FALSE,FALSE,FALSE,FALSE,FALSE,FALSE;FALSE,FALSE,FALSE,FALSE,FALSE,FALSE;#N/A,#N/A,#N/A,#N/A,#N/A,#N/A;FALSE,FALSE,FALSE,FALSE,FALSE,FALSE;FALSE,FALSE,FALSE,FALSE,FALSE,FALSE;FALSE,FALSE,FALSE,FALSE,FALSE,FALSE;#N/A,#N/A,#N/A,#N/A,#N/A,#N/A;FALSE,FALSE,FALSE,FALSE,FALSE,FALSE;FALSE,FALSE,FALSE,FALSE,FALSE,FALSE;FALSE,FALSE,FALSE,FALSE,FALSE,FALSE;FALSE,FALSE,FALSE,FALSE,FALSE,FALSE;FALSE,FALSE,FALSE,FALSE,FALSE,FALSE;FALSE,FALSE,FALSE,FALSE,FALSE,FALSE;#N/A,#N/A,#N/A,#N/A,#N/A,#N/A;FALSE,FALSE,FALSE,FALSE,FALSE,FALSE;FALSE,FALSE,FALSE,FALSE,FALSE,FALSE;FALSE,FALSE,FALSE,FALSE,FALSE,FALSE;FALSE,FALSE,FALSE,FALSE,FALSE,FALSE;FALSE,FALSE,FALSE,FALSE,FALSE,FALSE;FALSE,FALSE,FALSE,FALSE,FALSE,FALSE;FALSE,FALSE,FALSE,FALSE,FALSE,FALSE;FALSE,FALSE,FALSE,FALSE,FALSE,FALSE;FALSE,FALSE,FALSE,FALSE,FALSE,FALSE;FALSE,FALSE,FALSE,FALSE,FALSE,FALSE;FALSE,FALSE,FALSE,FALSE,FALSE,FALSE}
这并不是我们想要的含有36个元素的数组。其原因是,传递给IF函数的两个数组维度不同,一个是37行1列数组,一个是6行6列的数组
因此,要执行我们想要的比较,必须首先重新将其维度调整为与另一个区域的维度相同。也就是说,这里要将37行1列数组调整为6行6列的数组。
简单地使用INDEX函数处理由FREQUENCY函数生成的数组,使用合适大小和值的数组传递给其row_num参数,结果数组将是一个由6行6列组成的数组。
这里由FREQUENCY函数生成的37行1列数组:
{3;15;0;0;3;0;0;6;0;0;0;0;0;0;5;0;0;0;3;0;0;0;0;0;0;1;0;0;0;0;0;0;0;0;0;0;0}
要转换成下面的6行6列数组:
{3,15,0,0,3,0;0,6,0,0,0,0;0,0,5,0,0,0;3,0,0,0,0,0;0,1,0,0,0,0;0,0,0,0,0,0}
这将通过将一个数组传递给INDEX函数的参数row_num来实现,这个作为参数值的数组为:
{1,2,3,4,5,6;7,8,9,10,11,12;13,14,15,16,17,18;19,20,21,22,23,24;25,26,27,28,29,30;31,32,33,34,35,36}
那么,如何生成这个数组呢?
有许多方法,下面是其中的一种:
COLUMNS(Range1)*Arry2-TRANSPOSE(COLUMNS(Range1)-Arry1)
其中,名称Arry1:
=ROW(INDIRECT(“1:”&COLUMNS(Range1)))
转换为:
{1;2;3;4;5;6}
名称:Arry2:
=ROW(INDIRECT(“1:”&ROWS(Range1)))
转换为:
{1;2;3;4;5;6}
将其代入上面的公式中:
COLUMNS(Range1)*{1;2;3;4;5;6}-TRANSPOSE(COLUMNS(Range1)-{1;2;3;4;5;6})
由于示例中Range1的列数为6,故公式转换为:
6*{1;2;3;4;5;6}-TRANSPOSE(6-{1;2;3;4;5;6})
转换为:
6*{1;2;3;4;5;6}-TRANSPOSE({5;4;3;2;1;0})
转换为:
6*{1;2;3;4;5;6}-{5,4,3,2,1,0}
转换为:
{6;12;18;24;30;36}-{5,4,3,2,1,0}
正交的两个数组相减,得到:
{1,2,3,4,5,6;7,8,9,10,11,12;13,14,15,16,17,18;19,20,21,22,23,24;25,26,27,28,29,30;31,32,33,34,35,36}
这正是我们需要的。
现在,如上所述,我们将此数组作为参数row_num的值传递给INDEX函数。这里,确保我采用了必要的技术来强制INDEX对一组值进行操作(更多信息,请参见《Excel公式技巧03:INDEX函数,给公式提供数组》),因此:
INDEX(FREQUENCY(0+(Range1&0),0+(Range1&0)),N(IF(1,COLUMNS(Range1)*Arry2-TRANSPOSE(COLUMNS(Range1)-Arry1))))
转换为:
INDEX({3;15;0;0;3;0;0;6;0;0;0;0;0;0;5;0;0;0;3;0;0;0;0;0;0;1;0;0;0;0;0;0;0;0;0;0;0},{1,2,3,4,5,6;7,8,9,10,11,12;13,14,15,16,17,18;19,20,21,22,23,24;25,26,27,28,29,30;31,32,33,34,35,36})
得到:
{3,15,0,0,3,0;0,6,0,0,0,0;0,0,5,0,0,0;3,0,0,0,0,0;0,1,0,0,0,0;0,0,0,0,0,0}
再回到公式的主要构造:
MIN(IF(IF(Range1<>””,COUNTIF(Range1,Range1)+1/(Range1*10^6))=LARGE(IF(INDEX(FREQUENCY(0+(Range1&0),0+(Range1&0)),N(IF(1,COLUMNS(Range1)*Arry2-TRANSPOSE(COLUMNS(Range1)-Arry1)))),IF(Range1<>””,COUNTIF(Range1,Range1)+1/(Range1*10^6))),ROWS($1:1)),Range1))
将上面生成的中间结果代入:
MIN(IF({3.000001,FALSE,3.000001,FALSE,3.00000016666667,3.00000016666667;3.000001,6.0000002,FALSE,FALSE,FALSE,3.00000016666667;FALSE,FALSE,5.0000005,5.0000005,5.0000005,FALSE;3.00000025,3.00000025,FALSE,FALSE,FALSE,5.0000005;FALSE,1.00000033333333,FALSE,3.00000025,FALSE,FALSE;6.0000002,6.0000002,6.0000002,6.0000002,6.0000002,5.0000005}=LARGE(IF({3,15,0,0,3,0;0,6,0,0,0,0;0,0,5,0,0,0;3,0,0,0,0,0;0,1,0,0,0,0;0,0,0,0,0,0},{3.000001,FALSE,3.000001,FALSE,3.00000016666667,3.00000016666667;3.000001,6.0000002,FALSE,FALSE,FALSE,3.00000016666667;FALSE,FALSE,5.0000005,5.0000005,5.0000005,FALSE;3.00000025,3.00000025,FALSE,FALSE,FALSE,5.0000005;FALSE,1.00000033333333,FALSE,3.00000025,FALSE,FALSE;6.0000002,6.0000002,6.0000002,6.0000002,6.0000002,5.0000005}),ROWS($1:1)),Range1))
转换为:
MIN(IF({3.000001,FALSE,3.000001,FALSE,3.00000016666667,3.00000016666667;3.000001,6.0000002,FALSE,FALSE,FALSE,3.00000016666667;FALSE,FALSE,5.0000005,5.0000005,5.0000005,FALSE;3.00000025,3.00000025,FALSE,FALSE,FALSE,5.0000005;FALSE,1.00000033333333,FALSE,3.00000025,FALSE,FALSE;6.0000002,6.0000002,6.0000002,6.0000002,6.0000002,5.0000005}=LARGE({3.000001,FALSE,FALSE,FALSE,3.00000016666667,FALSE;FALSE,6.0000002,FALSE,FALSE,FALSE,FALSE;FALSE,FALSE,5.0000005,FALSE,FALSE,FALSE;3.00000025,FALSE,FALSE,FALSE,FALSE,FALSE;FALSE,1.00000033333333,FALSE,FALSE,FALSE,FALSE;FALSE,FALSE,FALSE,FALSE,FALSE,FALSE},ROWS($1:1)),Range1))
这里ROWS($1:1)=1,转换为:
MIN(IF({3.000001,FALSE,3.000001,FALSE,3.00000016666667,3.00000016666667;3.000001,6.0000002,FALSE,FALSE,FALSE,3.00000016666667;FALSE,FALSE,5.0000005,5.0000005,5.0000005,FALSE;3.00000025,3.00000025,FALSE,FALSE,FALSE,5.0000005;FALSE,1.00000033333333,FALSE,3.00000025,FALSE,FALSE;6.0000002,6.0000002,6.0000002,6.0000002,6.0000002,5.0000005}=6.0000002,Range1))
转换为:
MIN(IF({FALSE,FALSE,FALSE,FALSE,FALSE,FALSE;FALSE,TRUE,FALSE,FALSE,FALSE,FALSE;FALSE,FALSE,FALSE,FALSE,FALSE,FALSE;FALSE,FALSE,FALSE,FALSE,FALSE,FALSE;FALSE,FALSE,FALSE,FALSE,FALSE,FALSE;TRUE,TRUE,TRUE,TRUE,TRUE,FALSE},Range1))
代入Range1:
MIN(IF({FALSE,FALSE,FALSE,FALSE,FALSE,FALSE;FALSE,TRUE,FALSE,FALSE,FALSE,FALSE;FALSE,FALSE,FALSE,FALSE,FALSE,FALSE;FALSE,FALSE,FALSE,FALSE,FALSE,FALSE;FALSE,FALSE,FALSE,FALSE,FALSE,FALSE;TRUE,TRUE,TRUE,TRUE,TRUE,FALSE},{1,0,1,0,6,6;1,5,0,0,0,6;0,0,2,2,2,0;4,4,0,0,0,2;0,3,0,4,0,0;5,5,5,5,5,2}))
转换为:
MIN({FALSE,FALSE,FALSE,FALSE,FALSE,FALSE;FALSE,5,FALSE,FALSE,FALSE,FALSE;FALSE,FALSE,FALSE,FALSE,FALSE,FALSE;FALSE,FALSE,FALSE,FALSE,FALSE,FALSE;FALSE,FALSE,FALSE,FALSE,FALSE,FALSE;5,5,5,5,5,FALSE})
得到:
5
小结
这里的将单列数组转换成二维数组的技巧让我印象深刻,对FREQUENCY函数的使用也很好。







