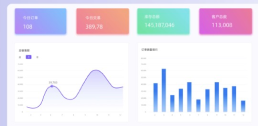
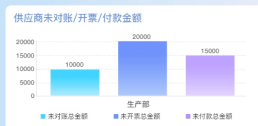
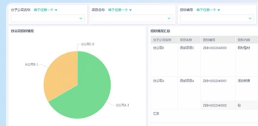
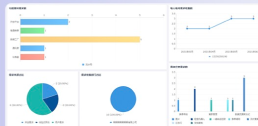
hadoop是什么
Hadoop是什么?它是一个开源的、分布式计算平台,专门设计用来处理大规模数据。Hadoop最初由雅虎的Doug Cutting和Mike Cafarella开发,后来成为Apache软件基金会的顶级项目。Hadoop由HDFS(Hadoop分布式文件系统)和MapReduce两部分组成,这两部分都可以在廉价的商用硬件上运行,从而降低了大规模数据处理的成本。

Hadoop能够高效地处理大规模数据,原因在于其分布式处理的能力。它能够将数据分布到多个节点上,并行处理数据,大大提高了数据处理的效率。这也意味着即使一个节点出现故障,也不会影响整个系统的稳定性,从而保证数据的安全性和可靠性。
Hadoop可以用来存储和处理不同种类的数据,包括结构化数据、半结构化数据和非结构化数据。这意味着它可以用来处理各种数据类型,满足不同应用场景的需求。Hadoop还具有很高的扩展性,能够方便地扩展到数千台服务器上,从而适应不断增长的数据规模。
除了HDFS和MapReduce,Hadoop生态系统还包括许多其他组件,如HBase、Hive、Pig、Spark等等。这些组件能够为Hadoop提供更丰富的功能,比如实时数据处理、数据仓库和数据挖掘等。因此,Hadoop不仅仅是一个简单的大数据处理平台,更是一个完整的大数据解决方案。

在当今的信息时代,数据正以前所未有的速度增长。企业和组织需要借助先进的技术手段来处理这些庞大的数据,以便从中获取有用的信息和见解。Hadoop作为一种先进的大数据处理平台,正是应对这一挑战的有效工具。
无论是互联网公司、金融机构还是制造业企业,都可以借助Hadoop来实现对海量数据的高效处理和分析。借助Hadoop,企业能够更好地理解市场和客户需求,改善产品和服务,提高业务绩效。因此,Hadoop被认为是大数据时代的重要技术基石之一。
当然,Hadoop作为一种先进的技术,也有其局限性。例如,Hadoop处理实时数据的能力相对较弱,因此不适合高实时性的应用场景。此外,Hadoop的部署和维护也需要较高的技术水平,对企业来说可能有一定的门槛。
总的来说,Hadoop是一种强大的大数据处理平台,它能够有效地处理大规模数据,满足不同类型数据的处理需求,为企业和组织提供了重要的数据处理工具。虽然Hadoop并不是完美的解决方案,但它无疑是大数据时代不可或缺的重要工具之一。随着技术的不断发展,相信Hadoop将会在未来有更广泛的应用和发展空间。